Recent Posts
-
(Partially) Repairing a Super NES Classic
My friend’s SNES Classic stopped responding to controller inputs. He reset it to factory settings but couldn’t even get through the language selection menu without being able to push buttons.
I told him I could take a look.
First I used Hakchi to save a backup of its internal storage.
Then I flashed the factory kernel and system software and erased the user partition. Same thing. Controller did nothing.
I tried my own controllers to no avail. And his controller worked in mine, so the issue was with the console itself.
How do we debug further?
The SNES Classic runs Linux on a somewhat mainstream ARM A7 SOC by Allwinner, and if you use Hakchi to flash its custom kernel, you can telnet to the device while it’s running and interrogate it.
Unfortunately, I didn’t keep great logs of this part of the process, but eventually I noticed something suspicious in
dmesg:[ -.------] twi_start()434 - [i2c1] START can't sendout!That message comes from the Allwinner SOC i2c-sunxi kernel driver in /drivers/i2c/busses/i2c-sunxi.c.
Oh no, an I²C start packet timeout sounds more like a hardware failure than anything my friend did with Hakchi. The SNES Classic controllers (and all Wii Nunchuk connectors) communicate with I²C (or TWI if you prefer that name). It’s time to pop open the case.

The inside of the case. With the case open and the heatsink off, there’s not much to it.

The unshielded board with labeled components. The SOC is a four-core Allwinner R16 with a Mali GPU. It’s quite a capable little chip.
You can also see the DRAM (Nanya NT5CC128M16IP-DI), flash (Macronix NT5CC128M16IP-DI), and PMIC (X-Powers/Allwinner AXP223) on the top of the board. The HDMI circuitry (Explore EP952) is on the bottom.
Most of that’s irrelevant - the important part was whether I could find anything wrong with the I²C signals between the connector and the SOC.
I won’t bore you with all of the random stuff I probed, but I eventually noticed that controller 1’s SCL line had a low-impedance path to ground, about 670 ohms. SDA and both of controller 2’s signal lines were pulled low at 1 MΩ, which makes a lot more sense.
Having the clock incorrectly pulled low would explain why it couldn’t communicate with controller 1. So where is the fault? It’s either somewhere in the PCB (unlikely) or in the SOC’s I²C buffer.
If the PCB, that’s easily fixable: cut traces and bodge a wire from the closest good point. If it’s in the SOC, that’s something I can’t fix. I don’t have the skill to reball and resolder BGA. While you can easily acquire an Allwinner R16 on Alibaba, there’s no way I could reball and solder it to the board without breaking something else. I did find a service that does BGA rework but it starts at $200 and the SNES Classic isn’t worth that much.
It was a little hard to trace the path from the connectors to the SOC because the traces run on inner layers. Eventually, I found some jumpers to desolder to isolate the fault.

Labeled I²C jumpers. I desoldered SCL1’s jumper – well, let’s be honest. I melted that tiny sucker into a black paste while struggling to apply even heat. Unfortunately, SCL1’s short to ground is in the chip and I can’t fix that.
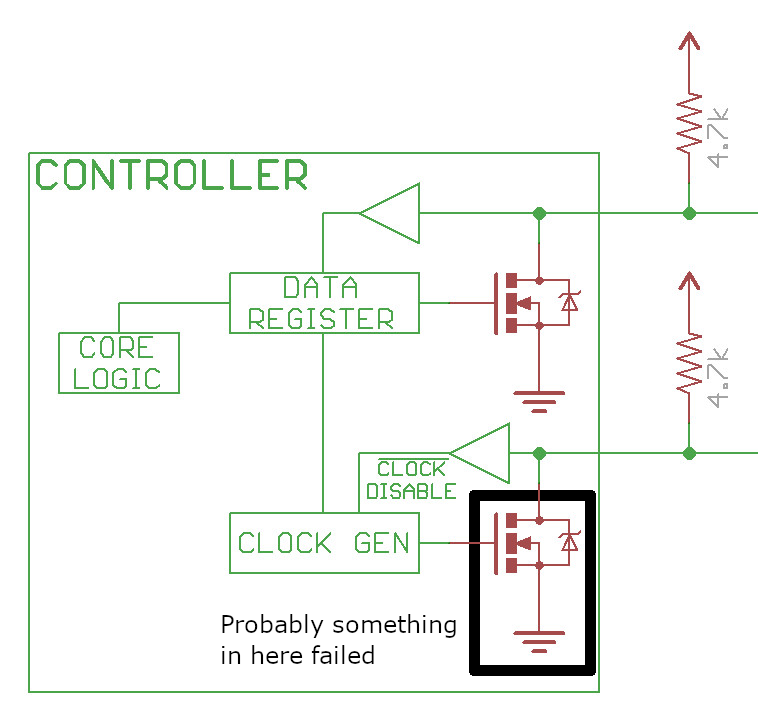
Likely a FET in the I²C buffer failed. At this point, software fixes became the only option.
I was wondering if you could patch the Hakchi kernel to swap controller 1 with controller 2. It may not even be hard. Then at least one controller would function.
But I also saw someone on Reddit mention that the system supports receiving power over USB while acting as a USB host with a powered USB On-The-Go cable. You can build your own O2G cable with wire snips, a soldering iron, and heat shrink tubing. I just purchased one from Amazon instead. The reviews make it clear this is a popular purpose for the cable.

Powered USB O2G Cable The stock Nintendo kernel does not support USB controllers but the latest Hakchi kernel does! I confirmed an Xbox controller can navigate the menu and every button works in game. Even better, controller port 2 still works as usual!
I wonder if raphnet’s Classic to USB adapter would work so you could keep the SNES controller experience.
At this point, I declared as much victory as this was going to get and sent it back to my friend. It’s nice to keep quality hardware out of the e-waste bin.
It works! -
Unsafe Rust Is Harder Than C
Or: The Most Expensive Linked List I’ve Ever Written
Some of you already know the contents of this post, especially if you’ve written embedded or unsafe code in Rust. But I didn’t, so I thought it was useful to write down my experience as accurately as I can. Without further ado…
Last year, I wrote Photohash, software to help me index my NAS and find duplicate photos with rotation-independent hashing and perceptual hashing. To make use of cores and keep the disks busy, it distributes work to compute and IO workers. Work is distributed with channels – synchronized work queues.
In Photohash, work tends to be discovered and processed in batches: enumerating directories returns multiple entries and the database is updated in multi-row transactions.
Rust has a rich selection of channel implementations: std::sync::mpsc, futures::channel, tokio::sync, crossbeam::channel, flume, and kanal are high-quality options.
Unfortunately, none of them exactly met my needs, so I nerd-sniped myself into writing my dream channel. My previous day job (EdenFS and Watchman) was full of ad-hoc channels so I knew roughly I wanted.
kanalis closest, but it is riddled with unsafe code and uses spinlocks which look great in microbenchmarks but have no place in userspace software.Introducing batch-channel, a throughput-optimized channel. The design goals are:
- Multi-producer, multi-consumer. Parallelism in both production and consumption.
- Sync and async support for both consumers and producers. Mix-and-match provides flexibility for use in any type of thread pool, async runtime, or FFI.
- Bounded or unbounded. Bounded for backpressure and limiting peak memory consumption. Unbounded for situations where you cannot guarantee deadlock freedom.
- Sending and receiving multiple values. I often want to send multiple values. Like reading all of the paths in a directory. Or writing multiple rows to a database. Batching allows amortizing per-batch costs. It’s silly to acquire the channel lock N times to push N values. It’s the same on the consumption side: workers may want to pull all pending work items in one channel read. You might wonder about lock-free queues, and they have their place, but but you’ll still contend on the head and tail, and atomic operations remain slow even on modern Intel cores. If you’re going to contend on the queue anyway, batch-channel’s philosophy is to stick the whole thing behind a mutex and maximize batch sizes on both ends.
At the time this was written, the following design goals weren’t yet implemented:
- Priorities. Senders can influence processing order.
- Bounding variable-sized items. For example, being able to say a queue can hold up to 20 MB of paths, no matter how long they are.
And, finally, the design goal that led to this post:
- No allocations under steady-state use. Allocations are a source of contention, failure, and overhead, especially when using slow system allocators.
The Shape of a Channel
To explain why unsafe Rust is even involved, let’s look at the implementation of a channel.
pub struct Channel<T> { q: VecDeque<T>, // Blocked receivers waiting_for_elements: Vec<Waker>, // Blocked senders waiting_for_capacity: Vec<Waker>, // Synchronous use requires some condition variables too. }When an async receiver blocks on
recv()because the channel is empty, the task’sWakeris stored so that the channel knows to wake it when a value arrives.Wakeris a handle to a blocked task. The channel can signal the async runtime to wake a task when it should poll the channel again. It’s a wide pointer, two words in size.Wakeris used like this:pub struct Recv<'a, T> { channel: &'a Channel<T>, } impl<'a, T> Future for Recv<'a, T> { type Output = T; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { // Is the queue empty? if let Some(element) = self.channel.q.pop_front() { // The queue has an element, so return it. Poll::Ready(element) } else { // Queue is empty so block and try again later. self.channel.waiting_for_elements.push(cx.waker().clone()); Poll::Pending } } }Note: The above code is illustrative. In reality, the channel has a
Mutexand some condition variables, but that’s incidental for this post.If the queue is empty when
recv()is called, the waker is stored in the channel and the task enters the blocked state.Later, when a value is added to the queue, any waiting tasks are woken:
fn send<T>(channel: &mut Channel<T>, value: T) { channel.q.push_back(value); let wakers = mem::take(&mut channel.waiting_for_elements); // NOTE: Mutexes are released here, before waking. // Unless we are clever with cancellation, we have to wake all futures, // because we don't know which, if any, will attempt the next poll. for waker in wakers { waker.wake(); } }Here’s the issue:
waiting_for_elementsis aVec<Waker>. The channel cannot know how many tasks are blocked, so we can’t use a fixed-size array. Using aVecmeans we allocate memory every time we queue a waker. And that allocation is taken and released every time we have to wake.The result is that a naive implementation will allocate and free repeatedly under steady-state send and recv. That’s a lot of memory allocator traffic.
Can We Use an Intrusive List?
The optimization I want is, rather than allocating in a
Vecevery time a task is blocked on the queue, can we store the list ofWakers within the blocked futures themselves? We know that we only need to store as manyWakers as blocked futures, so that should work.It should look something like:
pub struct Channel<T> { q: VecDeque<T>, // Intrusive doubly-linked list head. waiting_for_elements: WakerList, } fn send<T>(channel: &Channel<T>, value: T) { channel.q.push_back(value); let wakers = channel.waiting_for_elements.extract_list(); // Release any mutex before waking. for waker in wakers { waker.wake(); } } pub struct Recv<'a, T> { channel: &'a Channel<T>, // Every Future gets a WakerSlot, which is an intrusive doubly-linked // list node protected by Channel's mutex. waker: WakerSlot, } impl<'a, T> Future for Recv<'a, T> { type Output = T; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { if let Some(element) = self.channel.q.pop_front() { Poll::Ready(element) } else { // Queue is empty so try again later. // Store the Waker in this Future by linking it into channel's list. self.channel.waiting_for_elements.link(&mut self.waker, cx.waker().clone()); Poll::Pending } } }And that’s about the limit of my fake illustrative code. It’s time to get into details. How do we express an intrusive linked list in Rust?
Intrusive List Crates
This isn’t a new idea. I looked for existing crates:
- intrusive-collections is popular, but list nodes must outlive the list itself. In my case, the future will never outlive the channel.
- futures-intrusive is a nice-looking crate that performs the same optimization, but does not meet my design goals.
- multilist is Patrick Walton’s pre-1.0 experiment. Interesting idea, but it allocates nodes on the heap.
There are two other production examples of this approach:
- lilos-list is part
of Cliff Biffle’s embedded operating system
lilos. It stores wakers with an intrusive
list. It’s close to what I wanted, but embedded OS code tends to
have its own concurrency model. In particular, it would take some
work to integrate it with standard library mutexes, and it calls
wakers while locks are held, which is a bad
idea.
On the other hand, since there are no threads in lilos, it can avoid
implementing
Sendand usestd::cell::Cellto temporarily perform mutations on otherwise shared references. - tokio stores its channel wakers in an intrusive linked list too. Its implementation has a surprising amount of code, but it’s closest to what I want. The point is moot: it’s an implementation detail not visible outside of Tokio. (See Alice Rhyl’s musings on the challenges of intrusive structures in Rust.)
Pinning
It’s time to write a crate.
I want the channel to store a
WakerListand each future to have aWakerSlotmember. Slots can be linked into the list and unlinked either on wake or future cancellation.WakerListandWakerSlotform a self-referential data structure. Self-referential data structures are a well-known challenge in Rust. They require unsafe code.In C++, this is relatively easy. You delete the move and copy operations and fix up the link pointers as appropriate.
So, at this point in my Rust journey, still thinking in C++, I assume “easy!”
I just need to disable movement with
!Unpin(actuallyPhantomPinned) and ensure all methods takePin<&mut WakerList>andPin<&mut WakerSlot>.Once you observe a
Pin<&mut T>, you can assume T will never move again. I’m not going to discussPinin depth – Jon Gjengset has an excellent video describing its rationale and usage.Here’s where things start to get hard. Pinning was added well after Rust 1.0 was stabilized. The language pervasively assumes values of any type can be moved with a memcpy, so writing a data structure that violates that assumption makes the public APIs themselves awkward.
Here’s what I tried first:
struct WakerSlot(...); struct WakerList(...); impl WakerList { fn link<'list : 'slot, 'slot>( self: Pin<&'list mut WakerList>, slot: Pin<&'slot mut WakerSlot>, ) }My thought was that the act of linking should constrain the “pinnedness” and the lifetimes: list must outlive slot. Alas, lifetimes don’t work like that. A function call cannot constrain the actual lifetimes of its parameters. The borrow checker will happily subset
'listand'slotuntil it proves whether it can satisfy the constraints. The result is that thelink’s definition above has no effect.The idea that lifetimes precisely match the lives of actual values is apparently a common misconception, and it resulted in some puzzling error messages.
(Writing a post like this after the fact feels weird because “of course it doesn’t work that way” but I’m faithfully documenting my learning process.)
Can
WakerSlotitself take a lifetime to the list it references?struct WakerList(...); struct WakerSlot<'list>(...); impl WakerSlot<'_> { fn new(list: &WakerList) -> WakerSlot<'_>; }This doesn’t work. If you pretend the WakerSlot has a reference to the WakerList, then you can never create a
&mut WakerListelsewhere, because Rust’s core lifetime rule is that you can either have one mut reference or many shared references but never both.I’m hoping this is possible and a reader leaves me a note.
When Panicking Isn’t Safe Enough
Conceptually,
linkandunlinkoperations take mutable references to both the list and slot. But I never found a way to satisfy all of the rules in the type system:WakerSlot’s lifetime parameter does not outlive its list.- Only one
&mutreference at a time. - Never
&mutand&simultaneously.
Here, I gave up on trying to express the rules in the type system and chose to assert at runtime. The runtime lifetime rules are:
WakerListmust be empty when dropped. Otherwise, slots would have pointers to invalid memory.WakerSlotmust be unlinked when dropped. Otherwise, the list references deallocated memory.Reporting these invariant violations with panic is not sufficient. Panics can be caught, but the program would remain in a state where safe code can access dangling pointers and cause undefined behavior (UB).
Therefore, when an invariant is violated, the program must abort.
But I can’t just call abort: I want this utility crate to be
[no_std], so it’s up to the calling program to decide how it aborts.The simplest solution I found was to panic from an
extern "C"function and let Rust translate that to an abort.#[allow(non_snake_case)] #[inline(never)] #[cold] extern "C" fn MUST_UNLINK_WakerSlot_BEFORE_DROP() -> ! { // panic! from extern "C" is an abort with an error message. panic!("Must unlink WakerSlot before drop") // Another option, at the cost of a tiny, stable, dependency, is // the `abort` crate. //abort::abort() }Structural Pinning
I elided this detail in the example code above, but
WakerListis intended to be accessed behind a mutex. However, neitherstd::sync::Mutexnorparking_lot::Mutexhave structural pinning. That is,lock()is&Mutex<T>onto&mut T, allowing T to be moved.I needed a safe API for getting
Pin<&mut T>fromPin<&Mutex<T>>.So I wrote the pinned-mutex crate which provides structurally-pinned
Mutex,MutexGuard, andCondvarwrappers.Note that there is a pinarcmutex crate that offers a
PinArcMutex<T>type roughly equivalent toPin<Arc<Mutex<T>>>except with structural pinning. But it allocates and you can’t drop inparking_lot’s mutex, which is faster and lighter than the standard library’s.We can imagine a future Rust version where pinning is more natural and has pervasive (or implicit) standard library support.
Pinning Ergonomics
Boats recently wrote a nice overview of why Pin is shaped the way it is and why it is painful to use.
And the internet is full of threads like “Pin Suffering Continues”.
If you want to use pinned APIs safely in your own code, you will need to depend on a pin-projection crate like pin-project or pin-project-lite. (And don’t forget pinned_drop!)
It works fine, but you end up with code that looks like the following.
let mut wakers = state.as_mut().project().base.project().rx_wakers.extract_some_wakers(); while wakers.wake_all() { let mut state = self.project_ref().state.lock(); wakers.extract_more(state.as_mut().base().project().rx_wakers); }Writing code this way is miserable. The compiler will guide you, but my mind was shouting “you know what I want, just do it” the whole time.
It Works!
Deep breath. Tests passed.
WakerListandWakerSlotprovide the interface I wanted, so I published them in a wakerset crate. It offers a safe, intrusive,no_stdlist of Wakers.With it, I could remove the main source of steady-state allocations in
batch_channel.It was time to polish it up and ensure I didn’t miss anything, and this blog post is only half-done.
Undefined Behavior, Sanitizers, and MIRI
One of my original goals for
batch-channelwas to avoid unsafe code.Unfortunately, two optimizations required it. Besides the intrusive list described above, the MPMC channel objects themselves are managed with two reference counts, one for senders and one for receivers. A split reference count is required: when one half of the channel is dropped, the channel is closed.
To simplify auditing, I placed all of this new unsafe code behind safe APIs and separate crates. They are:
Safe Rust, excepting compiler bugs and incorrectly-designed unsound APIs, has no undefined behavior. Unsafe Rust, on the other hand, removes the guardrails and opens a buffet of possible UB.
There are three ways you can deal with potential undefined behavior. In increasing order of happiness over time:
- Hope for the best and deal with potential bugs when they come up.
- Think carefully and convince yourself the code is correct.
- Automated sanitizers.
Fortunately, Rust supports sanitizers that detect various types of undefined behavior. The two most useful are ASan and TSan. C++ programmers are quite familiar with them at this point, and I consider them table stakes for any C or C++ project.
But Rust has one even better: MIRI. It catches violations of the Rust aliasing model, which is pickier than ASAN. Satisfying MIRI is where I spent most of my time.
Rust Aliasing Model
The first time I ran MIRI, it failed:
test link_and_notify_all ... error: Undefined Behavior: trying to retag from <254318> for SharedReadWrite permission at alloc88289[0x10], but that tag does not exist in the borrow stack for this location ... trying to retag from <254318> for SharedReadWrite permission at alloc88289[0x10], but that tag does not exist in the borrow stack for this location ... help: this indicates a potential bug in the program: it performed an invalid operation, but the Stacked Borrows rules it violated are still experimental help: see https://github.com/rust-lang/unsafe-code-guidelines/blob/master/wip/stacked-borrows.md for further informationStacked borrows? What’s all this?
Here, I realized my first mistake: I dove straight into unsafe Rust and should have read more in advance:
My other mistake was “thinking in C”. Being deeply familiar with C’s semantics wasn’t helpful here. In hindsight, it feels foolish to have assumed Rust’s aliasing model was similar to C’s. In C, usually, having pointers to values carries no meaning. Primarily you reason about pointer dereferencing operations.
For example, in C, this is perfectly legal if
p == q:void foo(int* p, const int* q) { printf("%d\n", *q); *p = 456; printf("%d\n", *q); // if p == q, prints 456 *(int*)q = 789; printf("%d\n", *p); // if p == q, prints 789 }constis “meaningless” in that it does not prevent the pointee from changing, so the compiler can’t optimize based on it.fn foo(a: &u32, b: &mut u32) { println!("{a}"); *b = 123; println!("{a}"); // always prints the same value as above }On the other hand, Rust’s primary aliasing rule is that, at any point, an object may have a unique
&mutreference to it or any number of shared&references, but never both.The optimizer will take advantage of that.
ais not reloaded from memory because the write tobcannot alias it.The aliasing rules in Rust are not fully defined. That’s part of what makes this hard. You have to write code assuming the most pessimal aliasing model.
Under the most pessimal aliasing rules, you have to assume taking a
&mutreference to a value immediately writes to it and continues to write to it as long as the reference lives. And if you have a shared reference, you have to assume the value is read at arbitrary times as long as any reference is held.Box::leak
Let’s start with the first confusing example I ran into:
let p = Box::leak(Box::new(MyThing::new())) as *mut MyThing; // later: let ref: &MyThing = *p; ref.method();MIRI failed, complaining that
pwas formed from the perpetual&mutreturned byBox::leakand therefore it’s UB to create a shared&MyThingreference to it at any point thenceforth.The fix was to allocate without forming a reference:
let p = Box::into_raw(MyThing::new()); // later: let ref: &MyThing = *p; ref.method();Note: This may have been a MIRI bug or the rules have since been relaxed, because I can no longer reproduce as of nightly-2024-06-12. Here’s where the memory model and aliasing rules not being defined caused some pain: when MIRI fails, it’s unclear whether it’s my fault or not. For example, given the
&mutwas immediately turned into a pointer, does the&mutreference still exist? There are multiple valid interpretations of the rules.Box::from_raw
OK, if you allocate some memory with
Box::into_raw, you’d expect to deallocate withBox::from_raw, right? That failed MIRI too.I ended up having to write:
unsafe { let ptr = ptr.as_ptr(); std::ptr::drop_in_place(ptr); std::alloc::dealloc( ptr as *mut u8, std::alloc::Layout::new::<Inner<T>>()); }Note: This may have also been a MIRI bug. It is no longer reproducible. I changed
splitrcto useBox::into_rawandBox::from_rawand it passes MIRI. I enabled MIRI in my CI so we’ll see if it breaks again going forward.Linkage, References, and Interior Mutability
That’s channel allocation and deallocation covered. Now let’s look at the intrusive pointers in
wakerset.In a linked list, every node has a linkage struct.
struct Pointers { next: *mut Pointers, prev: *mut Pointers, pinned: PhantomPinned, } struct WakerList { pointers: Pointers, } struct WakerSlot { pointers: Pointers, // Required to assert that this slot is never // unlinked from an unrelated list. owner: *mut WakerList, waker: Option<Waker>, }Now imagine two threads. Thread A holds a
&mut WakerListwith the intent to extract pending Wakers. Thread B happens to hold a&WakerSlotat the same time.It is UB for code traversing the pointers to form a
&mut WakerSlot(or even a&WakerSlot) if any thread might have a&mut WakerSlot, because this violates Rust’s aliasing rules. A&mutreference must always be exclusive, even if it is never dereferenced. This is the important difference with C.Because Rust reorders reads and writes based on its aliasing rules, you must never convert a pointer into a reference unless you know that nobody else has a conflicting reference.
We need to prevent the compiler from optimizing a
&WakerSlotinto early reads of thepointersandwakerfields.UnsafeCellis the tool to reach for. It introduces a “mutability barrier”, andUnsafeCell<Pointers>tells Rust not to cache reads. We are responsible for ensuring we won’t violate Rust’s aliasing rules when accessingPointers’s fields.struct WakerList { pointers: Pointers, } struct WakerSlot { // UnsafeCell: written by WakerList independent of // WakerSlot references pointers: UnsafeCell<Pointers>, // Required to assert that this slot is never // unlinked from an unrelated list. owner: *mut WakerList, waker: Option<Waker>, }A circular linked list means that only a slot reference is required to mutate the list, so I needed to enforce the guarantee that only one thread may access the
UnsafeCells at a time.I did this with an important, if subtle, API guarantee: all link and unlink operations take
&mut WakerList. If&mut WakerSlotwas sufficient to unlink, it could violate thread safety ifWakerListwas behind a mutex. (This also means thatWakerListdoes not require anUnsafeCell<Pointers>.)The
pinned-aliasablecrate solves a related problem: how do we define self-referential data structures with mutable references that do not miscompile? Read the motivation in the crate’s doc comments. It’s a situation required by async futures, which are self-referential and thus pinned, but have no desugaring. See the open Rust Issue #63818.Avoiding References Entirely
As mentioned, when traversing a linked list, it’s easy to form conflicting
&mutreferences to nodes. Consider this slightly contrived unlink example:let p = &slot.pointers as *mut Pointers; let next: &mut Pointers = *(*p).next; let prev: &mut Pointers = *(*p).prev; next.prev = prev as *mut Pointers; prev.next = next as *mut Pointers; (*p).next = ptr::null_mut(); (*p).prev = ptr::null_mut();If
slotis the only slot in the list, thennextandprevboth point to theWakerListand we’ve now formed two mut references to the same value, which is UB.In this particular case, we could ensure every pointer dereference occurs as a temporary. That limits the scope of each reference to each line.
let p = &slot.pointers as *mut Pointers; let next = (*p).next; let prev = (*p).prev; (*next).prev = prev; (*prev).next = next; (*p).next = ptr::null_mut(); (*p).prev = ptr::null_mut();But I just don’t trust myself to ensure, under all code paths, that I never have two references overlap, violating Rust’s aliasing rules.
It’s kind of miserable, but the safest approach is to avoid creating references entirely and operate entirely in the domain of pointer reads, writes, and offsets.
let nextp = addr_of_mut!((*node).next); let prevp = addr_of_mut!((*node).prev); let next = nextp.read(); let prev = prevp.read(); addr_of_mut!((*prev).next).write(next); addr_of_mut!((*next).prev).write(prev); nextp.write(ptr::null_mut()); prevp.write(ptr::null_mut());(So much syntax. Makes you appreciate C.)
addr_of_mut!is key: it computes a pointer to a place expression without forming a reference. There are gotchas: you can still accidentally form a reference within anaddr_of_mut!argument. Read the documentation.Note: As I publish this, Rust 1.82 introduces new syntax that allows replacing
addr_of_mut!with&raw mutandaddr_of!with&raw const. It’s not yet clear to me how much this prevents accidental reference creation.Despite the noise, to be safe, I ended up converting all of
WakerSetto pointer reads and writes. It’s not greppable: the code looks like it’s still full of pointer dereferences, but they’re withinaddr_of_mut!and the place expressions have the right shape.I think it was Patrick Walton who once proposed a sugar for unsafe Rust and pointers with a hypothetical
->operator. It would be convenient and easier on the eyes.Until the Rust memory model stabilizes further and the aliasing rules are well-defined, your best option is to integrate ASAN, TSAN, and MIRI (both stacked borrows and tree borrows) into your continuous integration for any project that contains unsafe code.
If your project is safe Rust but depends on a crate which makes heavy use of unsafe code, you should probably still enable sanitizers. I didn’t discover all UB in wakerset until it was integrated into batch-channel.
MIRI: Stacked Borrows and Tree Borrows
MIRI supports two aliasing models: stacked borrows and tree borrows.
I won’t attempt to describe them. They are different approaches with the same goal: formalize and validate the Rust memory model. Ralf Jung, Neven Villani, and all are doing amazing work. Without MIRI, it would be hard to trust unsafe Rust.
I decided to run both stacked and tree borrows and haven’t hit any false positives so far.
Active Research in Self-Referential Structures
This topic is an active work in progress. I hope this blog post is obsolete in two years.
Self-referential and pinned data structures are something of a hot topic right now. The Rust-for-Linux project, doing the kinds of things systems programs do, has
Pinergonomics and self-referential data structures near the top of their wishlist.In particular, pinned initialization problem. The Linux kernel has self-referential data structures and it is currently hard to initialize them with safe code. In
wakerset, I sidestepped this problem at the cost of a small amount of runtime inefficiency by givingWakerListtwo empty states: one that is moveable and one that is pinned. The former converts to the latter the first time it is used after pinning.y86-dev has a great blog post proposing Safe Pinned Initialization.
Conclusions
As much as this post might come across as a gripefest, I still think Rust is great. In particular, its composable safety. The result of my pain is a safe, efficient API. You can use
wakersetwithout any risk of undefined behavior.What I learned from this experience:
- Be extra careful with any use of
unsafe. - References, even if never used, are more dangerous than pointers in C.
- Pinning syntax is awful, but it feels like Rust could solve this someday.
UnsafeCellis required for intrusive structures.- I don’t know how to statically constrain lifetime relationships with intrusive structures, but maybe it’s possible? Avoiding the need for runtime assertions would be nice.
- MIRI, especially under multithreaded stress tests, is critical.
- Putting this in words was as hard as writing the code.
-
Terminal Latency on Windows
UPDATE 2024-04-15: Windows Terminal 1.19 contains a fix that reduces latency by half! It’s now competitive with WSLtty on my machine. Details in the GitHub Issue.
In 2009, I wrote about why MinTTY is the best terminal on Windows. Even today, that post is one of my most popular.
MinTTY in 2009 Since then, the terminal situation on Windows has improved:
- Cygwin defaults to MinTTY; you no longer need to manually install it.
- Windows added PTY support, obviating the need for offscreen console window hacks that add latency.
- Windows added basically full support for ANSI terminal sequences in both the legacy conhost.exe consoles and its new Windows Terminal.
- We now have a variety of terminals to choose from, even on Windows: Cmder, ConEmu, Alacritty, WezTerm, xterm.js (component of Visual Studio Code)
The beginning of a year is a great time to look at your tools and improve your environment.
I’d already enabled 24-bit color in all of my environments and streamlined my tmux config. It’s about time that I take a look at the newer terminals.
Roughly in order, I care about:
- Minimum feature set: 24-bit color, reasonable default fonts with emoji support, italics are nice.
- Input latency.
- Throughput at line rate, for example, when I
cata large file. - Support for multiple tabs in one window would be nice, but tmux suffices for me.
Which terminals should I test?
I considered the following.
- Legacy conhost.exe (also known as Windows Console), Windows 10 19045
- MinTTY (3.7.0)
- Alacritty (0.13.1)
- WezTerm (20240203-110809-5046fc22)
- Windows Terminal (1.18.10301.0)
Testing Features
Testing color and italics support is easy with my colortest.rs script. To test basic emoji, you can cat the Unicode emoji 1.0 emoji-data.txt. To test more advanced support, try the zero-width joiner list in the latest/ directory.
Terminal Emoji Font Attributes conhost.exe No No italics MinTTY Black and white All major attributes Alacritty Black and white Everything but double underline WezTerm Color All major attributes Windows Terminal Color All major attributes Everything but conhost.exe meets my bar.
It’s also worth noting that conhost.exe has a terrible default palette. The default yellow is a pukey green and dark blue is barely visible. You can change palettes, but defaults matter.
Conhost.exe Default Palette 
MinTTY Default Palette Latency
I set up two latency tests. One with an 80x50 blank window in the upper left corner of the screen. The other fullscreen, editing an Emacs command at the bottom of the screen.
Since latencies are additive, system configuration doesn’t matter as much as the absolute milliseconds of latency each terminal adds, but I’ll describe my entire setup and include total keypress-to-pixels latency.
- Windows 10
- Intel i7-4771 @ 3.5 GHz
- NVIDIA GTX 1060
- Keyboard: Sweet 16 Macro Pad
- Display: LG 27GP950-B at 4K, 120 Hz, adaptive sync
Measurement Methodology
With Is It Snappy?, I measured the number of frames between pressing a key and pixels changing on the screen.
To minimize ambiguity about when the key was pressed, I slammed a pencil’s eraser into the key, and always measured the key press as the second frame after contact. (The first frame was usually when the eraser barely touched the key. It would usually clear the activation depth by the second frame.)
I considered the latency to end when pixels just started to change on the screen. In practice, pixels take several 240 Hz frames to transition from black to white, but I consistently marked the beginning of that transition.
I took five measurements for each configuration and picked the median. Each measurement was relatively consistent, so average would have been a fine metric too. It doesn’t change the results below.
80x50
80x50 window, upper left of screen, cleared terminal, single keypress.
Confirmed window size with:
$ echo $(tput cols)x$(tput lines) 80x50Terminal Median Latency (ms) 240 Hz Camera Frames conhost.exe WSL1 33.3 8 MinTTY WSL1 33.3 8 conhost.exe Cygwin 41.3 10 MinTTY Cygwin 57.9 14 WezTerm cmd.exe 62.5 15 Alacritty WSL1 62.5 15 WezTerm WSL1 66.7 16 Windows Terminal WSL1 66.7 16 Fullscreen
Maximized emacs, editing a command in the bottom row of the terminal. I only tested WSL1 this time.
Terminal Median Latency (ms) 240 Hz Camera Frames conhost.exe 45.8 11 MinTTY 52.42 12 WezTerm 75 18 Windows Terminal 75 18 Alacritty 87.5 21 Throughput
I generated a 100,000-line file with:
$ yes "This sentence has forty-five (45) characters." | head -n 100000 > /tmp/lines.txtThen I measured the wall-clock duration of:
$ time cat /tmp/lines.txtThis benchmark captures the case that I accidentally dump a ton of output and I’m sitting there just waiting for the terminal to become responsive again. I have a gigabit internet connection, and it’s embarrassing to be CPU-bound instead of IO-bound.
I did include Cygwin in this test, just to have two different MinTTY datapoints.
Terminal Elapsed Time (s) MinTTY WSL1 0.57 MinTTY Cygwin 2.2 Windows Terminal 5.25 Alacritty 5.75 WezTerm 6.2 conhost.exe 21.8 I assume this means MinTTY throttles display updates in some way. Of course this is totally fine, because you couldn’t read the output either way.
To test the hypothesis that MinTTY was caching cell rendering by their contents, I also tried generating a file that rotated through different lines, with no effect.
with open("/tmp/lines2.txt", "w") as f: for i in range(100000): sentence="This sentence has forty-five (45) characters." print(sentence[i%len(sentence):]+sentence[:i%len(sentence)], file=f)CPU Usage During Repeated Keypresses
While making these measurements, I noticed some strange behaviors. My monitor runs at 120 Hz and animation and window dragging are generally smooth. But right after you start Alacritty, dragging the window animates at something like 30-60 frames per second. It’s noticeably chunkier. WezTerm does the same, but slightly worse. Maybe 20 frames per second.
I don’t know if I can blame the terminals themselves, because I sometimes experience this even with Notepad.exe too. But the choppiness stands out much more. Maybe something is CPU-bound in responding to window events?
This made me think of a new test: if I open a terminal and hold down the “a” button on autorepeat, how much CPU does the terminal consume?
To measure this, I set the terminal process’s affinity to my third physical core, and watched the CPU usage graph in Task Manager. Not a great methodology, but it gave a rough sense. Again, 80x50.
Terminal Percent of Core Private Bytes After Startup (KiB) conhost 0% 6,500 Alacritty 5% 74,000 MinTTY WSL1 10% 10,200 MinTTY Cygwin 10% 10,500 Windows Terminal 20% 73,700 WezTerm 85% 134,000 The WezTerm CPU usage has to be a bug. I’ll report it.
CPU Usage (Idle)
I often have a pile of idle terminals sitting around. I don’t want them to chew battery life. So let’s take a look at CPU Cycles Delta (courtesy of Process Explorer) with a fresh, idle WSL session.
Terminal Idle Cycles/s (Focused) Idle Cycles/s (Background) conhost ~900,000 0 Alacritty ~2,400,000 no difference WezTerm ~2,600,000 ~1,600,000 Windows Terminal ~55,000,000 ~6,100,000 MinTTY WSL1 ~120,000,000 no difference MinTTY Cygwin ~120,000,000 no difference These numbers aren’t great at all! For perspective, I have a pile of Firefox tabs open, some of them actively running JavaScript, and they’re “only” using a few hundred million cycles per second.
Raymond Chen once wrote a blog post about the importance of properly idling in the Windows Terminal Server days. You might have a dozen users logged into a host, and if a program is actively polling, it’s eating performance that others could use.
Today, we often run on batteries, so idling correctly still matters, but it seems to be something of a lost art. The only terminal that idles completely is the old conhost.exe.
The other lesson we can draw is that Microsoft’s own replacement for conhost.exe, Windows Terminal, uses over 10x the RAM, 60x the CPU when focused, and infinitely more CPU when idle.
Conclusions
conhost.exe consistently has the best latency, with MinTTY not much behind. MinTTY handily dominates the throughput test, supports all major ANSI character attributes, and has a better default palette.
As in 2009, I’d say MinTTY is still pretty great. (I should try to track down that idle CPU consumption. It feels more like a bug than a requirement.)
If you want to use MinTTY as the default terminal for WSL, install WSLtty.
The others all have slightly worse latencies, but they’re in a similar class. I’m particularly sensitive to latency, so I’d had a suspicion even before measuring. Maybe it’s some consequence of being GPU-accelerated? Out of curiousity, I put Windows Terminal in software-rendered mode, and it shaved perhaps 4 ms off (median of 62.5 ms, 15 frames). Perhaps just measurement noise.
While I’m going to stick with MinTTY, one thing is clear: there is room to improve all of the above.
-
My Minimal tmux Config
If you spend any significant time in a terminal, you’ve probably used tmux.
I’m writing this post for a few reasons:
- People have asked for my config.
- I see too many people wasting their time in the morning, rebuilding their session from the previous day.
- I felt I should justify the configuration to myself rather than setting options ad-hoc.
tmux is often paired with a persistent connection. There are two popular choices: Eternal Terminal and Mosh. The goal is to close your laptop at the end of the day, open it the next morning, and have everything where it was so you can immediately get back into flow.
Note: There are other options. WezTerm has built-in multiplexing, for example.
macOS + iTerm2 + Eternal Terminal + tmux Control Mode
If you use macOS, iTerm2 has deep tmux integration in the form of tmux Control Mode.
tmux windows map to iTerm2 tabs. Native tab navigation and scrollback (both scrolling and find) work just as you’d expect.
tmux control mode does expect a reliable stream channel, so if you want a connection that persists even when network connections are dropped, Mosh will not work. You’ll need Eternal Terminal.
If you use a Mac, this is an excellent configuration. I worked on EdenFS and Watchman for almost five years this way.
mosh + tmux
But now I use Windows and Linux and can’t use iTerm2, so tmux within Mosh it is.
I find tmux’s default keybindings a little awkward, and the colors simultaneously harsh and too minimal, so I made a configuration to match my tastes.
You can download the full .tmux.conf here.
(You can go crazy, but avoiding too much fanciness was my goal. If you want all the bling, install the Tmux Plugin Manager and things like tmux-powerline.
.tmux.conf
First, a small demonstration.
Despite all of the work I put into my recent post about 24-bit color in terminals, I do still use some with limited color support. macOS’s Terminal.app only supports the 256-color palette, and the Linux console only really supports 8. The following selects the correct
tmuxterminfo entry.# Detect the correct TERM value for new sessions. # if-shell uses /bin/sh, so bashisms like [[ do not work. if "[ $(tput colors) = 16777216 ]" { set -g default-terminal "tmux-direct" } { if "[ $(tput colors) = 256 ]" { set -g default-terminal "tmux-256color" } { set -g default-terminal "tmux" } }I prefer Emacs keybindings in both bash (readline) and tmux.
setw -g mode-keys emacsThe next setting is more legacy terminal insanity. On some (most?) terminals, programs cannot differentiate between a user pressing the escape key and the beginning of an escape sequence.
readlineandtmuxdefault to 500 ms, which adds noticeable latency in some terminals when using programs likevi.There’s no correct value here. Ideally, your terminal would use an unambiguous code for the escape key, like MinTTY.
set -s escape-time 200Let’s not be stingy with scrollback! Searching lots of history is worth spending megabytes.
# I can afford 50 MB of scrollback. # Measured on WSL 1 with: # yes $(python3 -c "print('y' * 80)") set -g history-limit 100000By default, if multiple clients connect to one tmux session, tmux will resize all of the windows to the smallest connected terminal.
This behavior is annoying, and it’s always an accident. Sometimes I’ll leave a temporary connection to a server from home and then another fullscreen connection from work will cram each window into 80x25.
The
aggressive-resizeoption applies this logic only to the currently-viewed window, not everything in the session.setw -g aggressive-resize onWindow titles don’t automatically forward to the whatever graphical terminal you’re using. Do that, and add the hostname, but keep it concise.
set -g set-titles on set -g set-titles-string "#h: #W"iTerm2 has this nice behavior where active tabs are visually marked so you can see, at a glance, which had recent activity. The following two options offer similar behavior. Setting
activity-actiontononedisables any audible ding or visible flash, leaving just a subtle indication in the status bar.set -g monitor-activity on set -g activity-action noneThe following is perhaps the most important part of my configuration: tab management. Like browsers and iTerm2, I want my tabs numbered. I want a single (modified) keypress to select a tab, and I want tabs automatically renumbered as they’re created, destroyed, and reordered.
I also want iTerm2-style previous- and next-tab keybindings.
# Match window numbers to the order of the keys on a keyboard. set -g base-index 1 setw -g pane-base-index 1 setw -g renumber-windows on # My tmux muscle memory still wants C-b 0 to select the first window. bind 0 select-window -t ":^" # Other terminals and web browsers use 9 to focus the final tab. bind 9 select-window -t ":$" bind -n "M-0" select-window -t ":^" bind -n "M-1" select-window -t ":1" bind -n "M-2" select-window -t ":2" bind -n "M-3" select-window -t ":3" bind -n "M-4" select-window -t ":4" bind -n "M-5" select-window -t ":5" bind -n "M-6" select-window -t ":6" bind -n "M-7" select-window -t ":7" bind -n "M-8" select-window -t ":8" # Browsers also select last tab with M-9. bind -n "M-9" select-window -t ":$" # Match iTerm2. bind -n "M-{" previous-window bind -n "M-}" next-windowNote that Emacs assigns meaning to Alt-number. If it matters to you, pick a different modifier.
Now let’s optimize the window ordering. By default,
C-b ccreates a new window at the end. That’s a fine default. But sometimes I want a new window right after the current one, so defineC-b C-c. Also, add some key bindings for sliding the current window around.bind "C-c" new-window -a bind "S-Left" { swap-window -t -1 select-window -t -1 } bind "S-Right" { swap-window -t +1 select-window -t +1 }I wanted “C-{“ and “C-}” but terminal key encoding doesn’t work like that.
Next, let’s define some additional key bindings for very common operations.
By default, searching in the scrollback requires entering “copy mode” with
C-b [and then entering reverse search mode withC-r. Searching is common, so give it a dedicatedC-b r.bind r { copy-mode command-prompt -i -p "(search up)" \ "send-keys -X search-backward-incremental '%%%'" }And some convenient toggles:
# Toggle terminal mouse support. bind m set-option -g mouse \; display "Mouse: #{?mouse,ON,OFF}" # Toggle status bar. Useful for fullscreen focus. bind t set-option statusNow the status bar. The default status bar is okay, but we can do better.

tmux status bar: before - Move the tmux session ID next to the hostname on the right side.
- Move the current time to the far right corner.
- Keep the date, but I think I can remember what year it is.
- Ensure there is a single space between the windows and the left edge. Without a space at the edge, it looks weird.

tmux status bar: after The other half of that improvement is the color scheme. Instead of a harsh black-on-green, I chose a scheme that evokes old amber CRT phosphors or gas plasma displays My dad had a “laptop” with one of those when I was young.
The following color scheme mildly highlights the current window and uses a dark blue for the hostname-and-time section. These colors don’t distract me when I’m not working, but if I do look, the important information is there.
if "[ $(tput colors) -ge 256 ]" { set -g status-left-style "fg=black bg=colour130" set -g status-right-style "bg=colour17 fg=orange" set -g status-style "fg=black bg=colour130" set -g message-style "fg=black bg=colour172" # Current window should be slightly brighter. set -g window-status-current-style "fg=black bg=colour172" # Windows with activity should be very subtly highlighted. set -g window-status-activity-style "fg=colour17 bg=colour130" set -g mode-style "fg=black bg=colour172" }And that’s it!
Again, feel free to copy the complete .tmux.conf.
Shell Integration
There’s one more config to mention: adding some shell aliases to .bashrc.
I sometimes want to look at or edit a file right next to my shell.
if [[ "$TMUX" ]]; then function lv() { tmux split-window -h less "$@" } function ev() { tmux split-window -h emacs "$@" } function lh() { tmux split-window -v less "$@" } function eh() { tmux split-window -v emacs "$@" } fi(You may notice the aliases use different meanings of horizontal and vertical than tmux. I don’t know, it feels like tmux is backwards, but that could be my brain.)
Happy multiplexing!
-
I Just Wanted Emacs to Look Nice — Using 24-Bit Color in Terminals
Thanks to some coworkers and David Wilson’s Emacs from Scratch playlist, I’ve been getting back into Emacs. The community is more vibrant than the last time I looked, and LSP brings modern completion and inline type checking.
David’s Emacs looks so fancy — I want nice colors and fonts too, especially my preferred themes like Solarized.
From desktop environments, Emacs automatically supports 24-bit color.
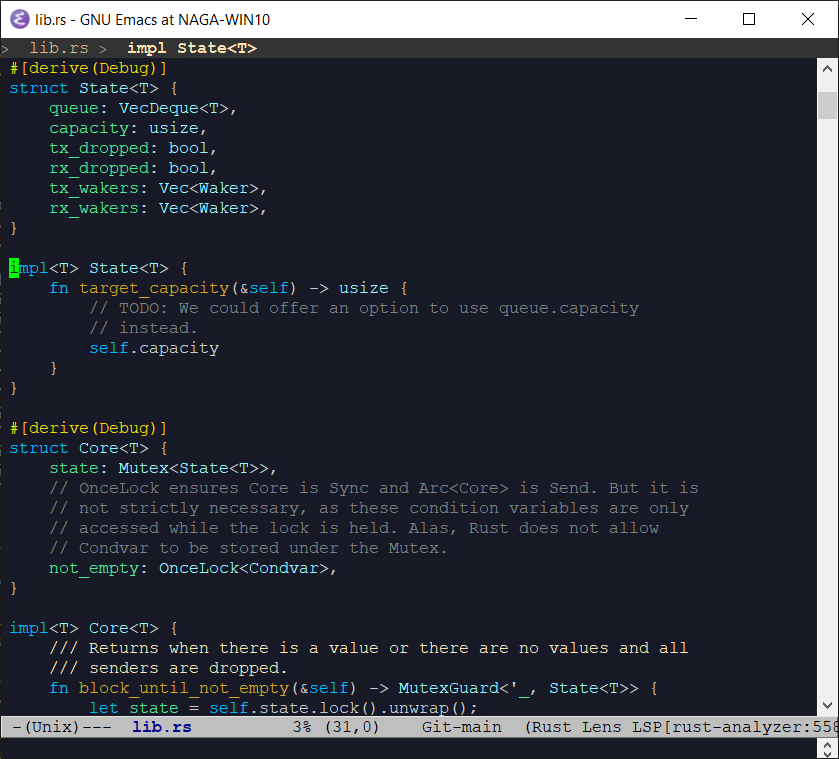
Graphical Emacs: Fonts and Colors But, since I work on infrastructure, I’ve lived primarily in terminals for years. And my Emacs looks like:
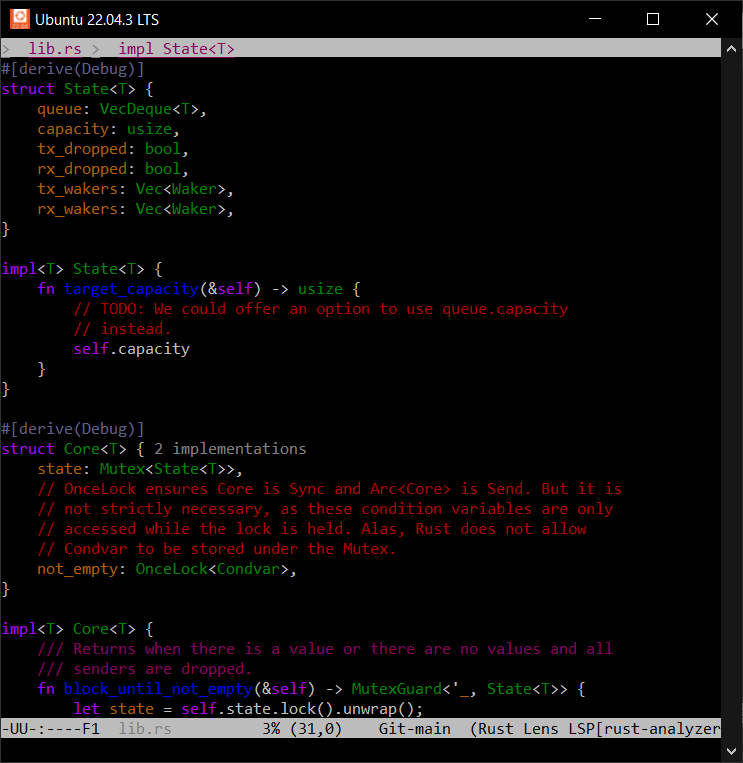
Terminal Emacs: Not Fancy It turns out, for years, popular terminals have supported 24-bit color. And yet they’re rarely used.
Like everything else, it boil down to legacy and politics. Control codes are a protocol, and changes to that protocol take time to propagate, especially with missteps along the way.
This post is two things:
- how to enable true-color support in the terminal environments I use, and
- how my desire for nice colors in Emacs led to poring over technical standards from the 70s, 80s, and 90s, wondering how we got to this point.
NOTE: I did my best, but please forgive any terminology slip-ups or false histories. I grew up on VGA text mode UIs, but never used a hardware terminal and wasn’t introduced to unix until much later.
ANSI Escape Codes
Early hardware terminals offered their own, incompatible, control code schemes. That made writing portable software hard, so ANSI standardized the protocol, while reserving room for expansion and vendor-specific capabilities.

DEC VT100 (1978) ANSI escape codes date back to the 70s. They cover a huge range of functionality, but since this post is focused on colors, I’m mostly interested in SGR (Select Graphics Rendition), which allows configuring a variety of character display attributes:
- bold or intensity
- italics (not frequently supported)
- blink
- foreground and background colors
- and a bunch of other stuff. You can look at Wikipedia.
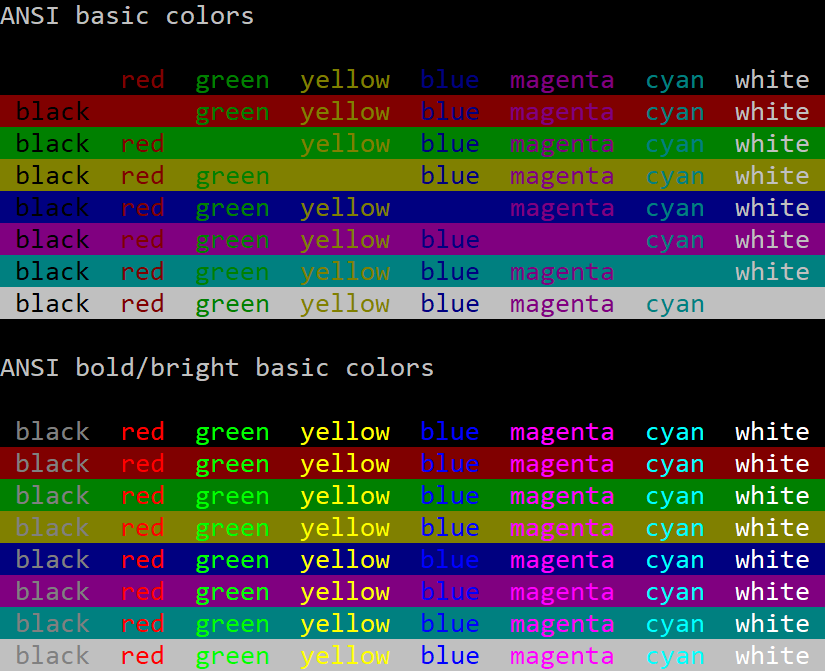
3-, 4-, and 8-bit Color
When color was introduced, there were eight. Black, white, the additive primaries, and the subtractive primaries. The eight corners of an RGB color cube.
Later, a bright (or bold) bit added eight more; “bright black” being dark gray.

4-Bit VGA Text Mode Palette In 1999, Todd Larason patched xterm to add support for 256 colors. He chose a palette that filled out the RGB color cube with a 6x6x6 interior sampling and added a 24-entry finer-precision grayscale ramp.
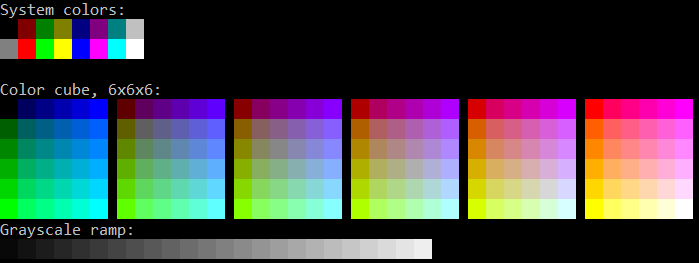
Output From colortest-256 NOTE: There’s a rare, but still-supported, 88-color variant with a 4x4x4 color cube and 8-entry grayscale ramp, primarily to reduce the use of historically-limited X11 color objects.
NOTE: We’ll debug this later, but Todd’s patch to add 256-color support to xterm used semicolons as the separator between the ANSI SGR command 48 and the color index, which set off a chain reaction of ambiguity we’re still dealing with today.
Where Did 24-Bit Color Support Come From?
It’s well-documented how to send 8-bit and 24-bit colors to compatible terminals. Per Wikipedia:
ESC[38;5;<n>msets foreground colornper the palettes above.ESC[38;2;<r>;<g>;<b>msets foreground color (r,g,b).(Again, that confusion about semicolons vs. colons, and an unused colorspace ID if colons are used. We’ll get to the bottom of that soon.)
But why 5? Why 2? How did any of this come about? I’d struggled enough with unexpected output that it was time to discover the ground truth.
Finding and reading original sources led me to construct the following narrative:
- In the 70s, ANSI standardized terminal escape sequences, resulting in ANSI X3.64 and the better-known ECMA-48.
- The first edition of ECMA-48 is lost to time, but it probably looks much like ANSI X3.64.
- The 2nd
edition
of ECMA-48 (1979) allocated SGR parameters 30-37 and 40-47 for setting
3-bit foreground and background colors, respectively.
- By the way, these standards use the word “parameter” to mean command, and “subparameter” to mean argument, if applicable.
- The 3rd edition (1984) introduced the concept of an implementation-defined default color for both foreground and background, and allocated parameters 39 and 49, respectively.
- Somewhere in this timeline, vendors did ship hardware terminals with richer color support. The Wyse WY-370 introduced new color modes, including a direct-indexed 64-color palette. (See Page 86 of its Programmer’s Guide.)
- 38 and 48 are the most important parameters for selecting colors
today, but they weren’t allocated by either the
4th
(1986) or
5th
(1991) editions. So where did they come from? The 5th edition gives
a clue:
reserved for future standardization; intended for setting character foreground colour as specified in ISO 8613-6 [CCITT Recommendation T.416]
-
ISO 8613 was a boondoggle of a project intended to standardize and replace all proprietary document file formats. You’ve never heard of it, so it obviously failed. But its legacy lives on – ISO 8613-6 (ITU T.416) (1993) built on ECMA-48’s codes and defined parameters 38 and 48 as extended foreground and background color modes, respectively.
The first parameter element indicates a choice between:
- 0 implementation defined (only applicable for the character foreground colour)
- 1 transparent;
- 2 direct colour in RGB space;
- 3 direct colour in CMY space;
- 4 direct colour in CMYK space;
- 5 indexed colour.
There we go! That is why 5 is used for 256-color mode and 2 is 24-bit RGB.
Careful reading also gives a clue as to the semicolon vs. colon syntax screw-up. Note the subtle use of the term “parameter element” vs. “parameter”.
If you read ISO 8613-6 (ITU T.416) and ECMA-48 closely, it’s not explicitly stated, but they seem to indicate that unknown parameters for commands like “select graphics rendition” should be ignored. And parameters are separated with semicolons.
That implies
ESC[38;5;3mshould be interpreted, in terminals that don’t support SGR 38, as “unknown, ignored (38)”, “blinking (5)”, and “italicized (3)”. The syntax should use colons to separate sub-parameter components, but something got lost along the way.(Now, in practice, programs are told how to communicate with their terminals via the TERM variable and the terminfo database, so I don’t know how much pain occurs in reality.)
Thomas Dickey has done a great job documenting the history of ncurses and xterm, and, lo and behold, explains exactly the origin of the ambiguous syntax:
We used semicolon (like other SGR parameters) for separating the R/G/B values in the escape sequence, since a copy of ITU T.416 (ISO-8613-6) which presumably clarified the use of colon for this feature was costly.
Using semicolon was incorrect because some applications could expect their parameters to be order-independent. As used for the R/G/B values, that was order-dependent. The relevant information, by the way, is part of ECMA-48 (not ITU T.416, as mentioned in Why only 16 (or 256) colors?). Quoting from section 5.4.2 of ECMA-48, page 12, and adding emphasis (not in the standard):
Each parameter sub-string consists of one or more bit combinations from 03/00 to 03/10; the bit combinations from 03/00 to 03/09 represent the digits ZERO to NINE; bit combination 03/10 may be used as a separator in a parameter sub-string, for example, to separate the fractional part of a decimal number from the integer part of that number.
and later on page 78, in 8.3.117 SGR – SELECT GRAPHIC RENDITION, the description of SGR 38:
(reserved for future standardization; intended for setting character foreground colour as specified in ISO 8613-6 [CCITT Recommendation T.416])
Of course you will immediately recognize that 03/10 is ASCII colon, and that ISO 8613-6 necessarily refers to the encoding in a parameter sub-string. Or perhaps you will not.
So it’s all because the ANSI and ISO standards are ridiculously expensive (to this day, these crappy PDF scans from the 90s and earlier are $200 USD!) and because they use a baroque syntax to denote ASCII characters. While writing this post, I had to keep
man asciiopen to match, for example,03/10to colon and03/11to semicolon. I guess it’s how standards were written back then. A Hacker News thread in the context of WezTerm gives more detail.So, to recap in the timeline:
- 1999: Thomas Dickey merged Todd Larason’s 256-color patches with ambiguous semicolon syntax.
- 2006: Konsole added support for 256-color and 24-bit truecolor using the same ambiguous syntax as xterm, with a follow-on discussion about colons vs. semicolons. The issue was noticed, but semicolon syntax was adopted anyway.
- 2012: Thomas Dickey fixed xterm to accept the standards-compliant syntax.
- 2016: Windows 10’s built-in console gained ANSI escape code support, including 24-bit colors. Unfortunately with the ambiguous semicolon syntax.
- 2019: Windows Terminal is released, with ANSI escape code support, but also using ambiguous semicolon syntax.
- 2022: Microsoft announced ecosystem-wide migration from the legacy framebuffer-based VGA-style console subsystem to ANSI terminal emulation, specifically using xterm as a guide.
- 2022: Konsole gains support for standards-compliant syntax.
Okay, here’s what we’ve established:
- ANSI codes are widely supported, even on Windows.
- Truecolor support is either widely supported or (for example, on the Linux text mode terminal) at least recognized and mapped to a more limited palette.
- Semicolon syntax is the most compatible, though the unambiguous colon syntax is slowly spreading.
I wrote a small colortest.rs program to test color support and attributes like reverse and italics to confirm the above in every terminal I use.
Terminfo
Now that we’ve established terminal capabilities and how to use them, the next trick is to convince software of varying lineages to detect and use the best color support available.
Typically, this is done with the old terminfo library (or the even older termcap).
Terminfo provides a database of terminal capabilities and the ability to generate appropriate escape sequences. The TERM environment variable tells programs which terminfo record to use. Its value is automatically forwarded over
sshconnections.Terminfo uses ridiculous command names:
infocmp,tic,toe. (Not to be confused with the unrelatedtac.)To see the list of terminfo records installed on your host, run
toe -a. (Do we /really/ need to install support for every legacy hardware terminal on modern machines? Good luck even finding a hardware terminal these days. They’re collector’s items.)infocmpis how you inspect the capabilities of a specific terminfo record.$ infocmp xterm-256color # Reconstructed via infocmp from file: /lib/terminfo/x/xterm-256color xterm-256color|xterm with 256 colors, am, bce, ccc, km, mc5i, mir, msgr, npc, xenl, colors#0x100, cols#80, it#8, lines#24, pairs#0x10000, acsc=``aaffggiijjkkllmmnnooppqqrrssttuuvvwwxxyyzz{{||}}~~, bel=^G, blink=\E[5m, bold=\E[1m, cbt=\E[Z, civis=\E[?25l, clear=\E[H\E[2J, cnorm=\E[?12l\E[?25h, cr=\r, csr=\E[%i%p1%d;%p2%dr, cub=\E[%p1%dD, cub1=^H, cud=\E[%p1%dB, cud1=\n, cuf=\E[%p1%dC, cuf1=\E[C, cup=\E[%i%p1%d;%p2%dH, cuu=\E[%p1%dA, cuu1=\E[A, cvvis=\E[?12;25h, dch=\E[%p1%dP, dch1=\E[P, dim=\E[2m, dl=\E[%p1%dM, dl1=\E[M, ech=\E[%p1%dX, ed=\E[J, el=\E[K, el1=\E[1K, flash=\E[?5h$<100/>\E[?5l, home=\E[H, hpa=\E[%i%p1%dG, ht=^I, hts=\EH, ich=\E[%p1%d@, il=\E[%p1%dL, il1=\E[L, ind=\n, indn=\E[%p1%dS, initc=\E]4;%p1%d;rgb:%p2%{255}%*%{1000}%/%2.2X/%p3%{255}%*%{1000}%/%2.2X/%p4%{255}%*%{1000}%/%2.2X\E\\, invis=\E[8m, is2=\E[!p\E[?3;4l\E[4l\E>, kDC=\E[3;2~, kEND=\E[1;2F, kHOM=\E[1;2H, kIC=\E[2;2~, kLFT=\E[1;2D, kNXT=\E[6;2~, kPRV=\E[5;2~, kRIT=\E[1;2C, ka1=\EOw, ka3=\EOy, kb2=\EOu, kbeg=\EOE, kbs=^?, kc1=\EOq, kc3=\EOs, kcbt=\E[Z, kcub1=\EOD, kcud1=\EOB, kcuf1=\EOC, kcuu1=\EOA, kdch1=\E[3~, kend=\EOF, kent=\EOM, kf1=\EOP, kf10=\E[21~, kf11=\E[23~, kf12=\E[24~, kf13=\E[1;2P, kf14=\E[1;2Q, kf15=\E[1;2R, kf16=\E[1;2S, kf17=\E[15;2~, kf18=\E[17;2~, kf19=\E[18;2~, kf2=\EOQ, kf20=\E[19;2~, kf21=\E[20;2~, kf22=\E[21;2~, kf23=\E[23;2~, kf24=\E[24;2~, kf25=\E[1;5P, kf26=\E[1;5Q, kf27=\E[1;5R, kf28=\E[1;5S, kf29=\E[15;5~, kf3=\EOR, kf30=\E[17;5~, kf31=\E[18;5~, kf32=\E[19;5~, kf33=\E[20;5~, kf34=\E[21;5~, kf35=\E[23;5~, kf36=\E[24;5~, kf37=\E[1;6P, kf38=\E[1;6Q, kf39=\E[1;6R, kf4=\EOS, kf40=\E[1;6S, kf41=\E[15;6~, kf42=\E[17;6~, kf43=\E[18;6~, kf44=\E[19;6~, kf45=\E[20;6~, kf46=\E[21;6~, kf47=\E[23;6~, kf48=\E[24;6~, kf49=\E[1;3P, kf5=\E[15~, kf50=\E[1;3Q, kf51=\E[1;3R, kf52=\E[1;3S, kf53=\E[15;3~, kf54=\E[17;3~, kf55=\E[18;3~, kf56=\E[19;3~, kf57=\E[20;3~, kf58=\E[21;3~, kf59=\E[23;3~, kf6=\E[17~, kf60=\E[24;3~, kf61=\E[1;4P, kf62=\E[1;4Q, kf63=\E[1;4R, kf7=\E[18~, kf8=\E[19~, kf9=\E[20~, khome=\EOH, kich1=\E[2~, kind=\E[1;2B, kmous=\E[<, knp=\E[6~, kpp=\E[5~, kri=\E[1;2A, mc0=\E[i, mc4=\E[4i, mc5=\E[5i, meml=\El, memu=\Em, mgc=\E[?69l, nel=\EE, oc=\E]104\007, op=\E[39;49m, rc=\E8, rep=%p1%c\E[%p2%{1}%-%db, rev=\E[7m, ri=\EM, rin=\E[%p1%dT, ritm=\E[23m, rmacs=\E(B, rmam=\E[?7l, rmcup=\E[?1049l\E[23;0;0t, rmir=\E[4l, rmkx=\E[?1l\E>, rmm=\E[?1034l, rmso=\E[27m, rmul=\E[24m, rs1=\Ec\E]104\007, rs2=\E[!p\E[?3;4l\E[4l\E>, sc=\E7, setab=\E[%?%p1%{8}%<%t4%p1%d%e%p1%{16}%<%t10%p1%{8}%-%d%e48;5;%p1%d%;m, setaf=\E[%?%p1%{8}%<%t3%p1%d%e%p1%{16}%<%t9%p1%{8}%-%d%e38;5;%p1%d%;m, sgr=%?%p9%t\E(0%e\E(B%;\E[0%?%p6%t;1%;%?%p5%t;2%;%?%p2%t;4%;%?%p1%p3%|%t;7%;%?%p4%t;5%;%?%p7%t;8%;m, sgr0=\E(B\E[m, sitm=\E[3m, smacs=\E(0, smam=\E[?7h, smcup=\E[?1049h\E[22;0;0t, smglp=\E[?69h\E[%i%p1%ds, smglr=\E[?69h\E[%i%p1%d;%p2%ds, smgrp=\E[?69h\E[%i;%p1%ds, smir=\E[4h, smkx=\E[?1h\E=, smm=\E[?1034h, smso=\E[7m, smul=\E[4m, tbc=\E[3g, u6=\E[%i%d;%dR, u7=\E[6n, u8=\E[?%[;0123456789]c, u9=\E[c, vpa=\E[%i%p1%dd,There’s so much junk in there. I wonder how much only applies to non-ANSI hardware terminals, and therefore is irrelevant these days.
For now, we’re only interested in three of these capabilities:
colorsis how many colors this terminal supports. The standard values are 0, 8, 16, 256, and 0x1000000 (24-bit), though other values exist.setafandsetabset foreground and background colors, respectively. I believe they stand for “Set ANSI Foreground” and “Set ANSI Background”. Each takes a single argument, the color number.
Those percent signs are a parameter arithmetic and substitution language. Let’s decode
setafin particular:setaf=\E[%?%p1%{8}%<%t3%p1%d%e%p1%{16}%<%t9%p1%{8}%-%d%e38;5;%p1%d%;mprint "\E[" if p1 < 8 { print "3" p1 } else if p1 < 16 { print "9" (p1 - 8) } else { print "38;5;" p1 } print "m"This is the
xterm-256colorterminfo description. It only knows how to output the ANSI 30-37 SGR parameters, the non-standard 90-97 brights (from IBM AIX), or otherwise the 256-entry palette, using ambiguous semicolon-delimited syntax.Let’s compare with
xterm-direct, the terminfo entry that supports RGB.$ infocmp xterm-256color xterm-direct comparing xterm-256color to xterm-direct. comparing booleans. ccc: T:F. comparing numbers. colors: 256, 16777216. comparing strings. initc: '\E]4;%p1%d;rgb:%p2%{255}%*%{1000}%/%2.2X/%p3%{255}%*%{1000}%/%2.2X/%p4%{255}%*%{1000}%/%2.2X\E\\', NULL. oc: '\E]104\007', NULL. rs1: '\Ec\E]104\007', '\Ec'. setab: '\E[%?%p1%{8}%<%t4%p1%d%e%p1%{16}%<%t10%p1%{8}%-%d%e48;5;%p1%d%;m', '\E[%?%p1%{8}%<%t4%p1%d%e48:2::%p1%{65536}%/%d:%p1%{256}%/%{255}%&%d:%p1%{255}%&%d%;m'. setaf: '\E[%?%p1%{8}%<%t3%p1%d%e%p1%{16}%<%t9%p1%{8}%-%d%e38;5;%p1%d%;m', '\E[%?%p1%{8}%<%t3%p1%d%e38:2::%p1%{65536}%/%d:%p1%{256}%/%{255}%&%d:%p1%{255}%&%d%;m'.A few things are notable:
xterm-directadvertises 16.7 million colors, as expected.xterm-directunsets thecccboolean, which indicates color indices cannot have new RGB values assigned.- Correspondingly, xterm-direct unsets
initc,oc, andrs1, also related to changing color values at runtime. - And of course
setafandsetabchange. We’ll decode that next.
Here’s where Terminfo’s limitations cause us trouble. Terminfo and ncurses are tied at the hip. Their programming model is that there are N palette entries, each of which has a default RGB value, and terminals may support overriding any palette entry’s RGB value.
The
-directterminals, however, are different. They represent 24-bit colors by pretending there are 16.7 million palette entries, each of which maps to the 8:8:8 RGB cube, but whose values cannot be changed.Now let’s look at the new
setaf:print "\E[" if p1 < 8 { print "3" p1 } else { print "38:2::" (p1 / 65536) ":" ((p1 / 256) & 255) ":" (p1 & 255) } print "m"It’s not quite as simple as direct RGB. For compatibility with programs that assume the meaning of
setaf, this scheme steals the darkest 7 blues, not including black, and uses them for compatibility with the basic ANSI 8 colors. Otherwise, there’s a risk of legacy programs outputting barely-visible dark blues instead of the ANSI colors they expect.One consequence is that the
-directschemes are incompatible with the-256colorschemes, so programs must be aware that 256 colors means indexed and 16.7 million means direct, except that the darkest 7 blues are to be avoided.Fundamentally, terminfo has no notion of color space. So a program that was written before terminfo even supported more colors than 256 might (validly!) assume the values of the first 8, 16, or even 256 palette entries.
This explains an issue with the Rust crate termwiz that I recently ran into at work. A program expected to output colors in the xterm-256color palette, but was actually generating various illegibly-dark shades of blue. (Note: Despite the fact that the issue is open as of this writing, @quark-zju landed a fix, so current termwiz behaves reasonably.)
This is a terminfo restriction, not a terminal restriction. As far as I know, every terminal that supports 24-bit color also supports the xterm 256-color palette and even dynamically changing their RGB values. (You can even animate the palette like The Secret of Monkey Island did!) While I appreciate Thomas Dickey’s dedication to accurately documenting history and preserving compatibility, terminfo simply isn’t great at accurate and timely descriptions of today’s vibrant ecosystem of terminal emulators.
Kovid Goyal, author of kitty, expresses his frustration:
To summarize, one cannot have both 256 and direct color support in one terminfo file.
Frustrated users of the ncurses library have only themselves to blame, for choosing to use such a bad library.
A deeper, more accurate discussion of the challenges are documented in kitty issue #879.
In an ideal world, terminfo would have introduced a brand new capability for 24-bit RGB, leaving the adjustable 256-color palette in place.
Modern programs should probably disregard most of terminfo and assume that 16.7 million colors implies support for the rest of the color capabilities. And maybe generate their own ANSI-compatible escape sequences… except for the next wrinkle.
Setting TERM: Semicolons Again!
Gripes about terminfo aside, everyone uses it, so we do need to ensure TERM is set correctly.
While I’d like to standardize on the colon-based SGR syntax, several terminals I use only support semicolons:
- Conhost, Windows’s built-in console.
- Mintty
claims to
work
(and wsltty does), but for some
reason running my colortest.rs
program
from Cygwin only works with semicolon syntax, unless I pipe the
output through
cator a file. There must be some kind of magic translation happening under the hood. I haven’t debugged. - Mosh is aware, but hasn’t added support.
- PuTTY.
- Ubuntu 22.04 LTS ships a version of Konsole that only supports semicolons.
Terminfo entries are built from “building blocks”, marked with a plus.
xterm+directis the building block for the standard colon-delimited syntax.xterm+indirectis the building block for legacy terminals that only support semicolon syntax.Searching for
xterm+indirectshows which terminfo entries might work for me.vscode-directlooks the most accurate. I assume that, since it targets a Microsoft terminal, it’s probably close enough in functionality to Windows Terminal and Windows Console. I have not audited all capabilities, but it seems to work.The next issue was that none of my servers had the
-directterminfo entries installed! On most systems, the terminfo database comes from thencurses-basepackage, but you needncurses-termfor the extended set of terminals.At work, we can configure a default set of installed packages for your hosts, but I have to install them manually on my unmanaged personal home machines. Also, I was still running Ubuntu 18, so I had to upgrade to a version that contained the
-directterminfo entries. (Of course, two of my headless machines failed to boot after upgrading, but that’s a different story.)Unfortunately, there is no terminfo entry for the Windows console.Since I started writing this post, ncurses introduced a winconsole terminfo entry, but it neither supports 24-bit color nor is released in any ncurses version.Configuring Emacs
Emacs documents how it detects truecolor support.
I find it helpful to
M-x eval-expression(display-color-cells)to confirm whether Emacs sees 16.7 million colors.Emacs also documents the
-directmode terminfo limitation described above:Terminals with ‘RGB’ capability treat pixels #000001 - #000007 as indexed colors to maintain backward compatibility with applications that are unaware of direct color mode. Therefore the seven darkest blue shades may not be available. If this is a problem, you can always use custom terminal definition with ‘setb24’ and ‘setf24’.
It’s worth noting that
RGBis Emacs’s fallback capability. Emacs looks for thesetf24andsetb24strings first, but no terminfo entries on my machine contain those capabilities:$ for t in $(toe -a | cut -f1); do if (infocmp "$t" | grep 'setf24') > /dev/null; then echo "$t"; fi; done $Nesting Terminals
conhost.exe (WSL1) +-------------------------+ | mosh | | +---------------------+ | | | tmux | | | | +-----------------+ | | | | | emacs terminal | | | | | | +-------------+ | | | | | | | $ ls | | | | | | | | foo bar baz | | | | | | | +-------------+ | | | | | +-----------------+ | | | +---------------------+ | +-------------------------+I’d never consciously considered this, but my typical workflow nests multiple terminals.
- I open a graphical terminal emulator on my local desktop, Windows, Mac, or Linux.
- I mosh to a remote machine or VM.
- I start tmux.
- I might then use a terminal within Emacs or
Asciinema or GNU
Screen.
- Yes, there are situations where it’s useful to have some screen sessions running inside or outside of tmux.
Each of those layers is its own implementation of the ANSI escape sequence state machine. For 24-bit color to work, every single layer has to understand and accurately translate the escape sequences from the inner TERM value’s terminfo to the outer terminfo.
Therefore, you need recent-enough versions of all of this software. Current LTS Ubuntus only ship with mosh 1.3, so I had to enable the mosh-dev PPA.
TERM must be set correctly within each terminal:
tmux-directwithin tmux, for example. There is no standard terminfo formosh, so you have to pick something close enough.Graphical Terminal Emulators
Most terminals either set TERM to a reasonable default or allow you to override TERM.
I use Konsole, but I think you could find a similar option in whichever you use.
Konsole's TERM value selection ssh
Often, the first thing I do when opening a terminal is to
sshsomewhere else. Fortunately, this is easy, as long as the remote host has the same terminfo record.sshcarries your TERM value into the new shell.tmux
But then you load
tmuxand TERM is set toscreen! To fix this, overridedefault-terminalin your~/.tmux.conf:set -g default-terminal "tmux-direct"For extra credit, consider setting
tmux-directconditionally with%ifwhen the outer TERM supports 24-bit color, otherwise leaving the default ofscreenortmux-256color. And then let me know how you did it. :Pmosh
While recent mosh does support 24-bit color, it only advertises 8 or 256 colors. Thus, it’s up to you to set TERM appropriately.
Mosh aims for xterm compatibility, but unfortunately only supports semicolon syntax for SGR 38 and 48, so
TERM=xterm-directdoes not work. So far, I’ve found thatvscode-directis the closest toxterm-direct.There is no convenient “I’m running in mosh” variable, so I wrote a
detect-mosh.rsRust script and called it from.bashrc:unamer=$(uname -r) unameo=$(uname -o) if [[ ! "$TMUX" ]]; then if [[ "$unamer" == *Microsoft ]]; then # WSL 1 export TERM=vscode-direct elif [[ "$unameo" == Cygwin ]]; then # Eh, could just configure mintty to set mintty-direct. export TERM=vscode-direct elif detect-mosh 2>/dev/null; then # This should be xterm-direct, but mosh does not understand SGR # colon syntax. export TERM=vscode-direct fi fiIt works by checking whether the shell process is a child of
mosh-server.The jury’s still out on whether it’s a good idea to compile Rust in the critical path of login, especially into an underpowered host like my Intel Atom NAS or a Raspberry Pi.
It Works!
Beautiful Emacs themes everywhere!
Emacs within tmux within mosh This was a ton of work, but I learned a lot, and, perhaps most importantly, I now feel confident I could debug any kind of wonky terminal behavior in the future.
To recap:
- Terminals don’t agree on syntax and capabilities.
- Terminfo is how those capabilities are queried.
- Terminfo is often limited, sometimes inaccurate, and new terminfo versions are released infrequently.
What’s Next?
If you were serious about writing software to take full advantage of modern terminal capabilities, it would be time to break from terminfo.
I imagine such a project would look like this:
- Continue to use the TERM variable because it’s well-supported.
- Give programs knowledge of terminals independent of the age of the
operating system or distribution they’re running on:
- Programs would link with a frequently-updated (Rust?) library.
- Said library would contain a (modern!) terminfo database representing, say, the last 10 years of terminal emulators, keyed on (name, version). Notably, the library would not pretend to support any hardware terminals, because they no longer exist. We can safely forget about padding, for example.
- Continue to support the terminfo file format and OS-provided terminfo files on disk, with some protocol for determining which information is most-up-to-date.
- Allow an opt-in TERMVERSION to differentiate between the capabilities of, for example, 2022’s Konsole and 2023’s Konsole.
- Allow describing modern terminal capabilities (like 24-bit color, 256-color palette animation, URL links, Kitty’s graphics protocol) in an accurate, unambiguous format, independent of the timeline of new ncurses releases.
- Backport modern terminal descriptions to legacy programs by
providing a program to be run by
.bashrcthat:- Uses TERM and TERMVERSION to generate a binary terminfo file in
$HOME/.terminfo/, which ncurses knows how to discover. - Generates unambiguous 24-bit color capabilities like
RGB,setf24, andsetb24, despite the fact that getting them added to terminfo has been politically untenable. - Otherwise, assumes RGB-unaware programs will assume the 256-color
palette, and leaves
colors#0x100,initc,ocin place. Palette animation is a useful, widely-supported feature.
- Uses TERM and TERMVERSION to generate a binary terminfo file in
Let me know if you’re interested in such a project!
