Writing a Fast JSON Parser
Several holidays ago, I got a bee in my bonnet and wrote a fast JSON parser whose parsed AST fits in a single contiguous block of memory. The code was small and simple and the performance was generally on-par with RapidJSON, so I stopped and moved on with my life.
Well, at the end of 2016, Rich Geldreich shared that he'd also written a high-performance JSON parser.
A while back I wrote a *really* fast JSON parser in C++ for fun, much faster than RapidJSON (in 2012 anyway). Is this useful tech to anyone?
— Rich Geldreich (@richgel999) December 18, 2016
I dropped his pjson into my benchmarking harness and discovered it was twice as fast as both RapidJSON and sajson! Coupled with some major JSON parsing performance problems in a project at work, I was nerd-sniped again.
I started reading his code but nothing looked particularly extraordinary. In fact, several things looked like they ought to be slower than sajson... Oh wait, what's this?
do {
c = pStr[0]; if (globals::s_parse_flags[c] & 1)
{ ++pStr; break; }
c = pStr[1]; if (globals::s_parse_flags[c] & 1)
{ pStr += 2; break; }
c = pStr[2]; if (globals::s_parse_flags[c] & 1)
{ pStr += 3; break; }
c = pStr[3];
pStr += 4;
} while (!(globals::s_parse_flags[c] & 1));
Why is unrolling that loop a win? How is the parse flags look-up (even L1 is 3-4 cycle latency) better than some independent comparisons?
Guess it was time to do some instruction dependency analysis!
Fast String Parsing
The problem at hand: given a pointer to the first byte after the opening quote of a string, find the first special byte, where special bytes are ", \, <0x20, or >0x7f.
The loop:
for (;;) {
if (*p < 0x20 || *p > 127 || *p == '"' || *p == '\\') {
break;
}
++p;
}
roughly breaks down into:
begin_loop:
load c, [p]
compare c, 0x20
jump-if-less exit_loop
compare c, 0x7f
jump-if-greater exit_loop
compare c, '"'
jump-if-equal exit_loop
compare c, '\\'
jump-if-equal exit_loop
increment p
jump begin_loop
exit_loop:
How do we think about the performance of this loop? Remember that mainstream CPUs are out-of-order and can execute four (or more!) instructions in parallel. So an approximate mental model for reasoning about CPU performance is that they understand multiple instructions per cycle, then stick them all into an execution engine that can execute multiple instructions per cycle. Instructions will execute simultaneously if they're independent of each other. If an instruction depends on the result of another, it must wait N cycles, where N is the first instruction's latency.
So, assuming all branches are correctly predicted (branch predictors operate in the frontend and don't count towards dependency chains), let's do a rough estimate of the cost of the loop above:
load c, [p] # depends on value of p
# assuming L1, ~4 cycle latency
# all four comparisons can be done in parallel
# assumption: jumps are all predicted
increment p
# jump to beginning
increment p is the only instruction on the critical path - it carries a dependency across iterations of the loop. Is there enough work to satisfy the execution resources during the increment? Well, the comparisons are independent so they can all be done in parallel, and there are four of them, so we can probably keep the execution units busy. But it does mean that, at most, we can only check one byte per cycle. In reality, we need to issue the load and increment too, so we're looking at a loop overhead of about 2-3 cycles per byte.
Now let's look more closely at Rich's code.
Replacing the comparisons with a lookup table increases comparison latency (3-4 cycles latency from L1) and increased comparison throughput (multiple loads can be issued per cycle).
So let's spell out the instructions for Rich's code (reordered for clarity):
begin_loop:
load c0, [p]
load c1, [p+1]
load c2, [p+2]
load c3, [p+3]
load t0, [is_plain_string+c0]
load t1, [is_plain_string+c1]
load t2, [is_plain_string+c2]
load t3, [is_plain_string+c3]
compare t0, 0
jump-if-equal exit_loop
compare t1, 0
jump-if-equal increment_1_and_exit_loop
compare t2, 0
jump-if-equal increment_2_and_exit_loop
compare t3, 0
jump-if-equal increment_3_and_exit_loop
add p, 4
jump begin_loop
increment_1_and_exit_loop:
add p, 1
jump exit_loop
increment_2_and_exit_loop:
add p, 2
jump exit_loop
increment_3_and_exit_loop:
add p, 3
exit_loop:
- Load four bytes per iteration [not on critical execution path]
- Load four LUT entries [not on critical execution path]
- Issue four comparisons per cycle [not on critical execution path]
- add p, 4
Again, the critical path is only add p, 4, but we still need to issue the other instructions. The difference is that now all of the loads happen in parallel and the comparisons for 4 bytes happen in parallel too, rather than doing four comparisons per byte.
It's still hard to say if this is a win on paper -- Haswell can only issue 2 loads per cycle. But the loads can overlap with the comparisons from previous bytes). However, we still have to issue all of these instructions. So maybe we're looking at something closer to 2 cycles per byte?
Empirically, at least on my Broadwell, replacing four comparisons with a LUT was definitely a win. 55cc213
But is unrolling the loop necessary? If I take out the unrolling but leave the LUT, clang gets slower but gcc stays the same. I checked - neither gcc nor clang do any automatic unrolling here. What's going on? Branch predictor effects? Also, Intel's Intel Architecture Code Analyzer tool says that the unrolled and non-unrolled loops are both frontend-bound and have the same loop throughput.
I'm not yet convinced that a tight dependency chain is why unrolling is a win. More investigation is required here. But the important thing to keep in mind is to pay attention to the critical path latency through a loop body as well as the number of independent operations that can soak up spare execution bandwidth.
Lead Bullets
After playing around with LUTs and unrolling, I started implementing a bunch of small optimizations that I'd long known were available but didn't consider to be that important.
Well, as it often turns out in performance projects, a sequence of 2% gains adds up to significant wins over time! If you've read Ben Horowitz's lead bullets story or how SQLite achieved a 50% speed up, this will sound familiar.
Here are the optimizations that mattered:
- Moved the input and output pointers into locals instead of members, which helps VC++ and Clang understand that they can be placed in registers. (gcc was already performing that optimization.) 71078d3 4a07c77
- Replaced the entire parse loop with a goto state machine. Surprisingly, not only was this a performance win, but it actually made the code clearer. 3828769 05b3ec8 c02cb31
- Change an 8-entry enum to a
uint8_tinstead of the pointer-sized value it was defaulting to. 799c55f - Duplicated a bit of code to avoid needing to call a function pointer. 44ec0df
- Tiny microoptimizations like avoiding branches and unnecessary data flow. 235d330 002ba31 193b183 c23fa23
- Store the tag bits at the bottom of the element index instead of the top, which avoids a shift on 64-bit. e7f2351
Static Branch Prediction
I also spent a bit of time on static branch prediction. It's a questionable optimization; in theory, you should just use profile-guided optimization (PGO) and/or rely on the CPU's branch predictors, but in practice few people actually bother to set up PGO. Plus, even though the CPU will quickly learn which branches are taken, the compiler doesn't know. Thus, by using static branch prediction hints, the compiler can line up the instructions so the hot path flows in a straight line and all the cold paths are off somewhere else, sometimes saving register motion in the hot path.
For some examples, look at these uses of SAJSON_LIKELY and SAJSON_UNLIKELY.
I can't recommend spending a lot of time on annotating your branches, but it does show up as a small but measurable win in benchmarks, especially on smaller and simpler CPUs.
Things I Didn't Do
- Unlike Rich's parser and RapidJSON, I chose not to optimize whitespace skipping. Why? Not worth the code size increase - the first thing someone who cares about JSON parsing performance does is minify the JSON. b05082b
- I haven't yet optimized number parsing. Both RapidJSON and Rich's parser are measurably faster there, and it would be straightforward to apply the techniques. But the documents I regularly deal with are strings and objects and rarely contain numbers.
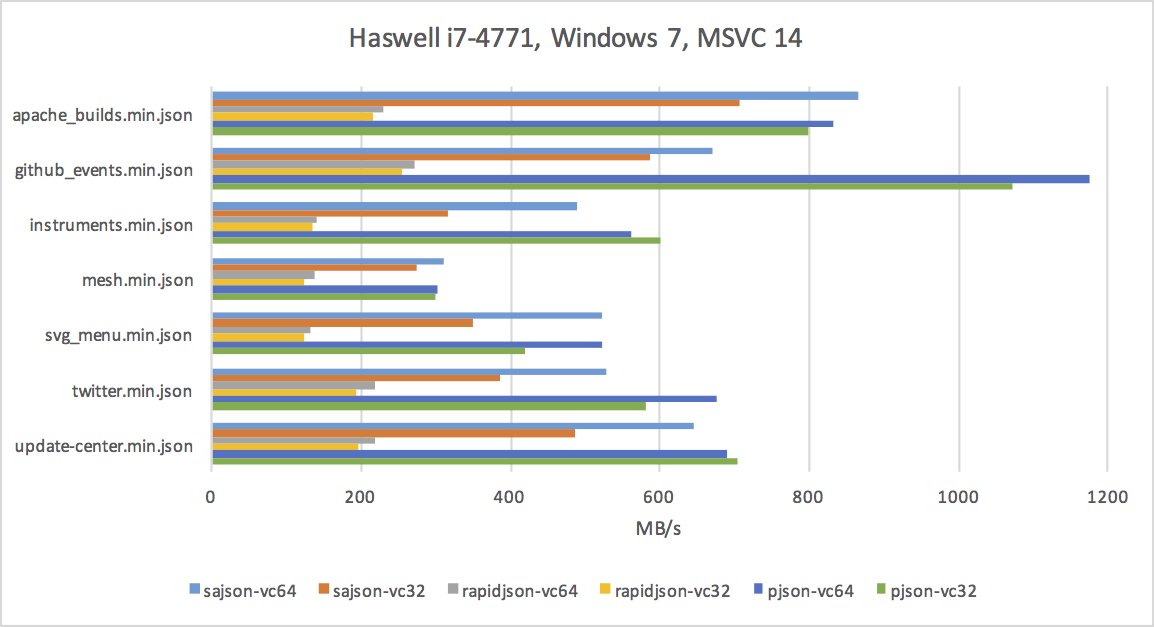
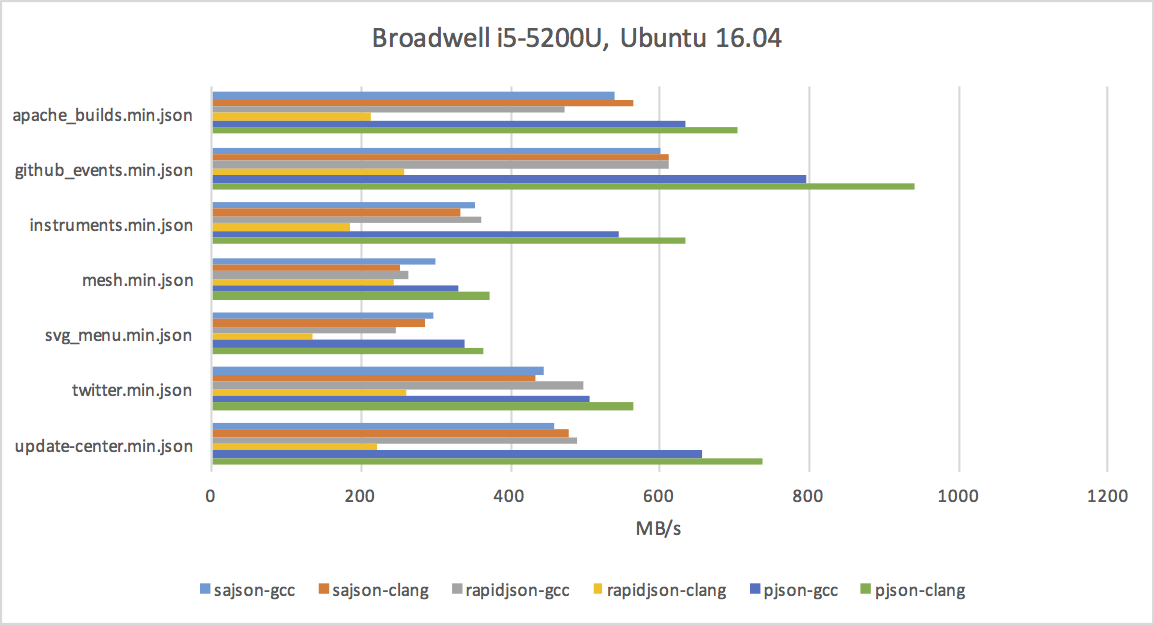
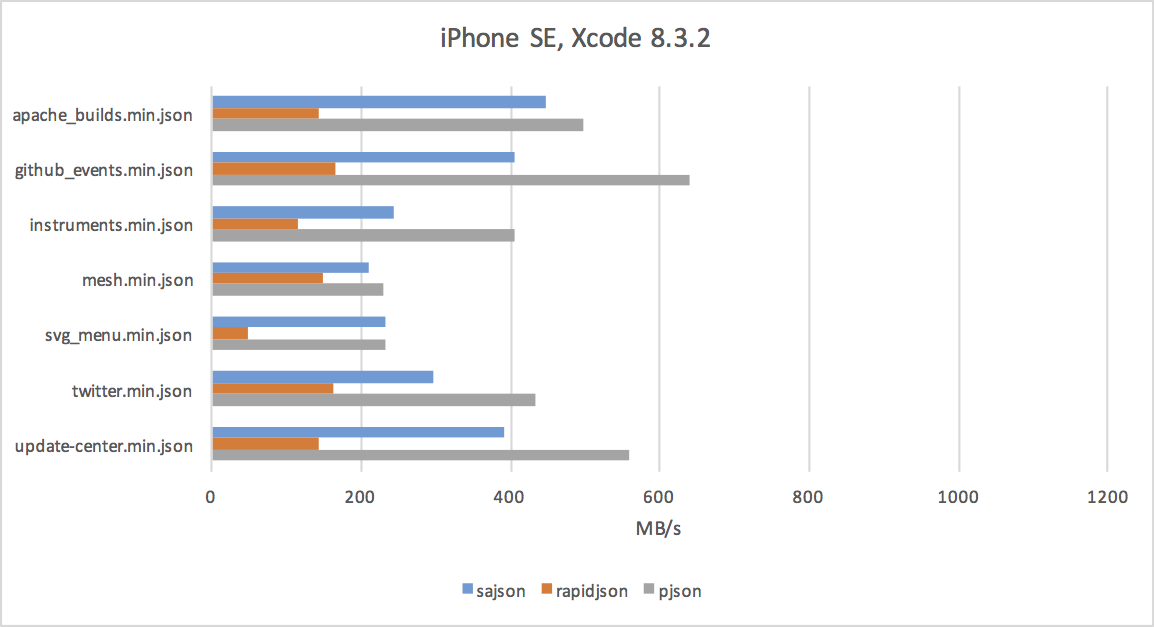
Benchmark Results
I tested on four devices: my desktop (high-clocked Haswell), laptop (low-clocked Broadwell), iPhone SE, and Atom-based home server.
Desktop
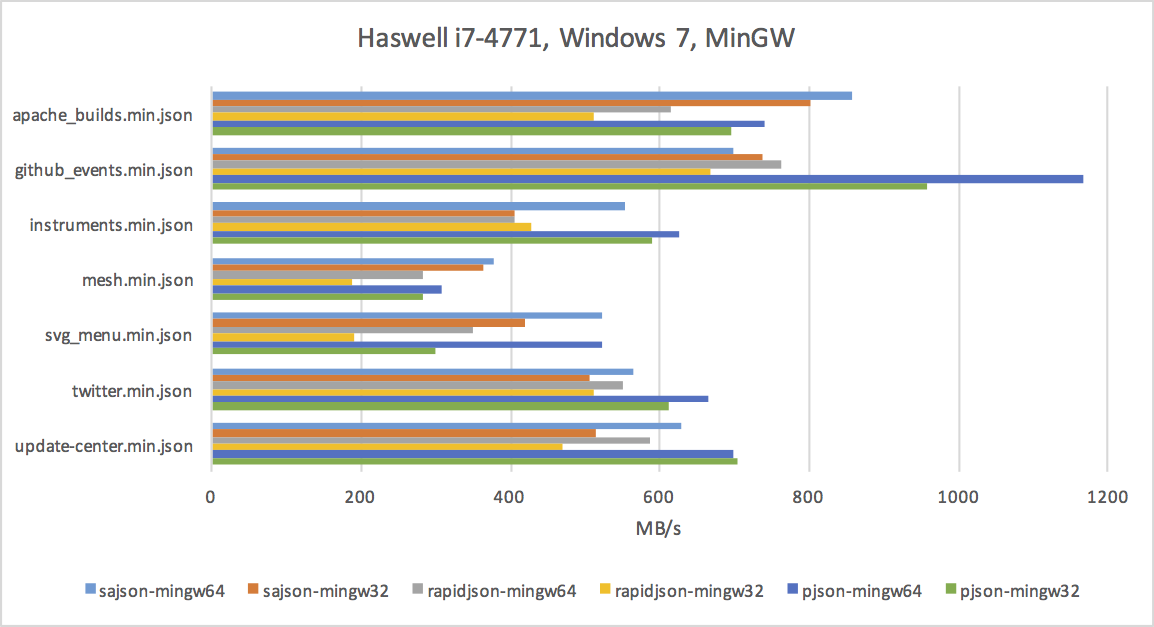
Dell XPS 13
iPhone SE
Atom D2700
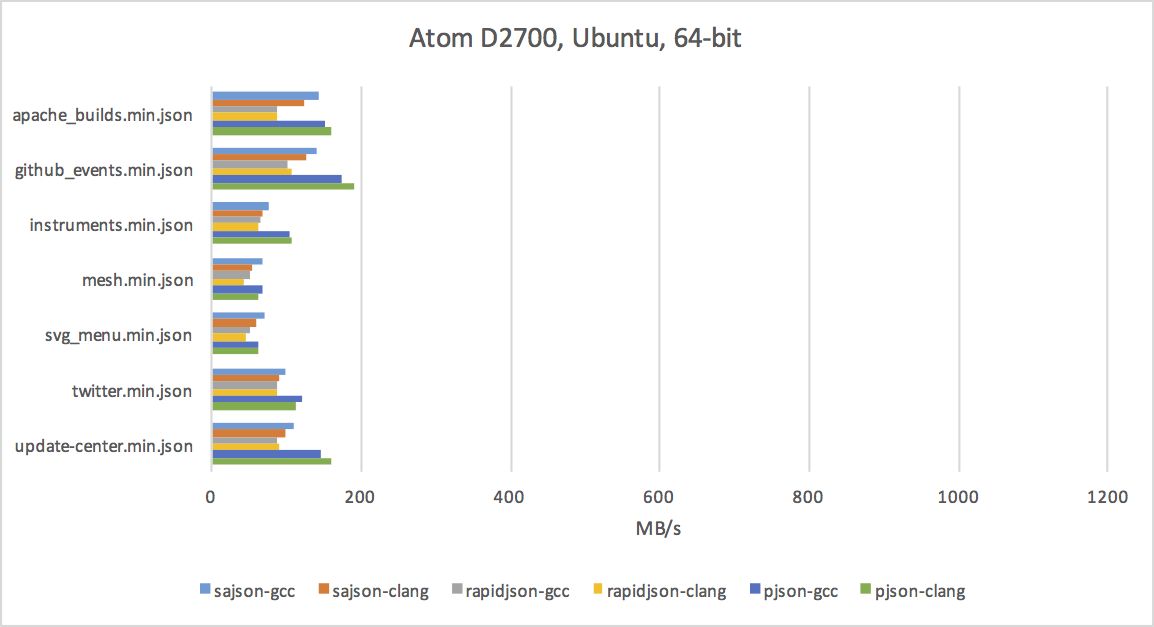
The charts aren't very attractive, but if you look closely, you'll notice a few things:
- Parsing JSON on modern CPUs can be done at a rate of hundreds of megabytes per second.
- gcc does a much better job with RapidJSON than either clang or MSVC.
- JSON parsing benefits from x64 - it's not a memory-bound or cache-bound problem, and the extra registers help a lot.
- The iPhone SE is not much slower than my laptop's Broadwell. :)
The Remainder of the Delta
As you can see in the charts above, sajson is often faster than RapidJSON, but still not as fast as Rich's pjson. Here are the reasons why:
sajson does not require the input buffer to be null-terminated, meaning that every pointer increment requires a comparison with the end of the buffer (to detect eof) in addition to the byte comparison itself. I've thought about changing this policy (or even adding a compile-time option) but I really like the idea that I can take a buffer straight from a disk mmap or database and pass it straight to sajson without copying. On the other hand, I measured about a 10% performance boost from avoiding length checks.
sajson sorts object keys so that object lookup takes logarithmic rather than linear time. The other high-performance parsers have linear-time object lookup by key. This is an optimization that, while not necessary for most use cases, avoids any accidental worst-case quadratic-time usage.
sajson's contiguous AST design requires, for every array, shifting N words in memory where N is the number of elements in the array. The alternative would be to use growable arrays in the AST (requiring that they get shifted as the array is realloc'd). Hard to say how much this matters.
Aside: The "You Can't Beat the Compiler" Myth
There's this persistent idea that compilers are smart and will magically turn your code into something that maps efficiently to the machine. That's only approximately true. It's really hard for compilers to prove the safety (or profitability) of certain transformations and, glancing through the produced code for sajson, I frequently noticed just plain dumb code generation. Like, instead of writing a constant into a known memory address, it would load a constant into a register, then jump to another location to OR it with another constant, and then jump somewhere else to write it to memory.
Also, just look at the charts - there are sometimes significant differences between the compilers on the same code. Compilers aren't perfect and they appreciate all the help you can give!
Benchmarking
Measuring the effect of microoptimizations on modern computers can be tricky. With dynamic clock frequencies and all of today's background tasks, the easiest way to get stable performance numbers is to take the fastest time from all the runs. Run your function a couple thousand times and record the minimum. Even tiny optimizations will show up this way.
(If a library that uses statistical techniques to automatically achieve precise results is readily available, consider using that.)
I also had my JSON benchmarks report MB/s, which normalizes the differences between test files of different sizes. It also helps understand parser startup cost (when testing small files) and the differences in parse speed between files with lots of numbers, strings, huge objects, etc.
Swift Bindings
Dropbox (primarily @aeidelson) contributed high-quality Swift bindings for sajson. The challenge in writing these bindings was finding a way to efficiently expose the sajson parse tree to Swift. It turns out that constructing Swift arrays and objects is REALLY expensive; we once benchmarked 10 ms in sajson's parser and 400 ms of Swift data structure construction.
Fortunately, Swift has decent APIs for unsafely manipulating pointers and memory, and with those we implemented the ability to access sajson AST nodes through a close-to-natural ValueReader type.
Converting sajson strings (e.g. ranges of UTF-8 memory) into Swift Strings is still expensive, but Swift 4 might improve the situation:
@jckarter @chadaustin We have new APIs for this on the 4.0 branch that I actually need to benchmark…
— Airspeed Velocity (@AirspeedSwift) May 19, 2017
An iOS team at Dropbox replaced JSONSerialization with sajson and cut their initial load times by two thirds!
Summary
I used to think JSON parsing was not something you ever wanted in your application's critical path. It's certainly not the kind of algorithm that modern computers love (read byte, branch, read byte, branch). That said, this problem has been beaten to death. We now have multiple parsers that can parse data at hundreds of megabytes per second -- around the same rate as SHA-256! If we relaxed some of the constraints on sajson, it could even go faster.
So how fast was Rich's parser, after all? When measured in Clang and MSVC, quite a lot, actually. But when measured in GCC, RapidJSON, sajson, and pjson were (and remain) very similar. Many of the differences come down to naive, manually-inlined code, which we know the compiler can reliably convert to a fast sequence of instructions. It's annoying to eschew abstractions and even duplicate logic across several locations, but, in the real world, people use real compilers. For critical infrastructure, it's worth taking on some manual optimization so your users don't have to care.
Update
Arseny Kapoulkine pointed out an awesome trick to me: replace the last byte of the buffer with 0, which lets you avoid comparing against the end of the buffer. When you come across a 0 byte, if it's the last one, treat it as if it's the byte that got replaced. This would be a material performance win in sajson _and_ avoid the need for specifying null-terminated buffers.See discussion on Hacker News (2017), Hacker News (2019), /r/cpp, /r/programming, and /r/rust.
It's possible that a SIMD implementation (assuming that you routinely pass over enough bytes) can blow this away. I'm not sure what the cross-over point is - it depends on whether you are falling out of this code quickly or not. Obviously using a big SIMD sequence to replace a "2 cycles per byte" implementation is pretty stupid if the SIMD sequence is "0.5 cycles a byte" but the fixed cost of using the SIMD means that your costs are >=16 cycles and the typical case is small.
It's also not clear that you actually need a SIMD instruction - if you've squashed your hotspot to the point that adding the complexity of per-platform SIMD specialization is only a small win, then why bother?
All that being said...
I've been really lazy in writing this up, but someone kindly did a decent write-up for us in the Rust reimplementation of our "Teddy" literal matcher. Please see https://github.com/rust-lang/regex/blob/master/src/simd_accel/teddy128.rs if interested or look up the Hyperscan project at https://github.com/01org/hyperscan for a few different versions of this trick.
Hi,
fast is good, but have you checked your parser for correctnesss? You may want to run it against this end of 2016 challenging JSON parser library: http://seriot.ch/parsing_json.php
Hermann.
Hi, good question. I've validated it against Milo Yip's excellent conformance tests, where it passes everything but the extreme numeric precision tests. (The JSON spec does not specify precision requirements, so I've considered that okay for now. Probably worth a look though.)
Your null termination problem is an oldie but a goodie. The Ragel state machine generator has a 'noend' option to purposely omits bounds checking.
If you're parsing mmap'd memory btw, and don't want to map it with write permissions, you can always just map an additional page beyond the end of the file. Most OS's guarantee this will always be zeroed out. Hell, you don't even have to do this if the file size isn't a multiple of the page size, since the padding in the final page is also zeroed.
The trick mentioned in the update is the Elephant in Cairo! https://en.m.wikipedia.org/wiki/ElephantinCairo
How does it compare to jsmn? http://zserge.com/jsmn.html Which gives 482MBps on http://zserge.com/jsmn.html
Project License API UTF-8 Neg. tests Followers Benchmark Finalist? Note yajl ISC SAX Y Y 815/120 249 MB/s, 5.1 s Y Large code base. jsonsl MIT SAX N Y 10/2 246 MB/s, 5.6 s Y Tiny source code base. Jansson MIT DOM Y Y 234/59 25 MB/s, 52 s Y cson BSD' DOM Y Y n/a 30 MB/s, 44 s Y json-c BSD DOM Y N 103/45 38 MB/s, 29.7 s Y json-parser BSD DOM N Y 276/24 49 MB/s, 12.4 s Y Tiny! A single source file. jsmn MIT custom N Y 65/4 16 MB/s, 3.3 s 482 MB/s, 2.3 s Y Tiny! js0n pub. custom N N 67/10 n/a N LibU BSD N 18/3 n/a N WJElement LGPL N 7/2 n/a N M's JSON parser LGPL N n/a n/a N cJSON BSD N n/a n/a N
Benchmark https://github.com/vlm/vlm-json-test
I've been wanting to write a JSON stream parser for a while. By the time the last packet arrives, the rest of the JSON will already be parsed. We have some large queries that download a few megabytes of JSON. It looks like CPUs and memory are getting fast enough that it may no longer make sense, though.
Thanks for the very interesting post.
It would be interesting to see performance on this benchmark. Chap here does use sse2 instructions if I recall right, and he is faster than RapidJSON.
https://github.com/kostya/benchmarks#json
Just in case you weren't aware, there's a statistics-based micro-benchmarking library for c++: nonius. Have a look: https://nonius.io
I've experimented a little with CSV parsing using AVX2, and had some good results, mainly on wider files. Specifically, I take the approach of doing a single preparse to produce a bitmap of places where there are delimiters. Can then parse the file in a normal loop more efficiently. No formal results as it doesn't yet have complete correctness, but initial testing looks promising. I'm not sure how JSON would go. https://github.com/jasonk000/csv-experiments/
[…] Decoder Speed How quickly can the entire file be scanned or processed? For comparison, JSON can be parsed at a rate of hundreds of MB/s. […]
[…] Chad Austin (via Hacker News): […]
I ran sajson with my JSONTestSuite and found it to be pretty good, except that some non-numbers are erroneously accepted as numbers.
I opened the following issue: https://github.com/chadaustin/sajson/issues/31
Thanks! I'll look into that.
I did benchmark of sajson, RapidJSON and gason using RapidJSON's nativebenchmark. The results were consistent with the Dell XPS 13 graph above, except that in my hands rapidjson-clang is comparable with others (here it's much slower than rapidjson-gcc). https://github.com/project-gemmi/benchmarking-json
Regarding benchmarking of microoptimization. SQLite has a writeup about it: https://www.sqlite.org/cpu.html The message is that the cycle count from Cachegrind that is only a proxy for actual performance, but is more repeatable than real timings, is actually better for microoptimizations. Because in this case repeatability is more important than accuracy.
Very nice, thanks for the heads up!