JSON Never Dies - An Efficient, Queryable Binary Encoding
A familiar story: Team starts project. Team uses JSON for interchange; it's easy and ubiquitous and debuggable. Project grows. Entity types multiply. Data sizes increase. Finally, team notices hundreds of kilobytes -- or even megabytes -- of JSON is being generated, transferred, and parsed.
"Just use a binary format!" the Internet cries.
But by the time a project gets to this stage, it's often a nontrivial amount of work to switch to Protocol Buffers or Cap'n Proto or Thrift or whatever. There might be thousands of lines of code for mapping model objects to and from JSON (that is arrays, objects, numbers, strings, and booleans). And if you're talking about some hand-rolled binary format, it's even worse: you need implementations for all of your languages and to make sure they're fuzzed and secure.
The fact is, the activation energy required to switch from JSON to something else is high enough that it rarely happens. The JSON data model tends to stick. However, if we could insert a single function into the network layer to represent JSON more efficiently, then that could be an easy, meaningful win.
"Another binary JSON? We already have CBOR, MsgPack, BSON, and UBSON!" the Internet cries.
True, but, at first glance, none of those formats actually seem all that great. JSON documents tend to repeat the same strings over and over again, but those formats don't support reusing string values or object shapes.
This led me to perform some experiments. What might a tighter binary representation of JSON look like?
What's in a format?
First, what are some interesting properties of a file format?
- Flexibility and Evolvability Well, we're talking about representing JSON here, so they're all going to be similar. However, some of the binary JSON replacements also have support for dates, binary blobs, and 64-bit integers.
- Size How efficiently is the information encoded in memory? Uncompressed size matters because it affects peak memory usage and it's how much data the post-decompression parser has to touch.
- Compressibility Since you often get some sort of LZ compression "for free" in the network or storage interface, there's value in the representation being amenable to those compression algorithms.
- Code Size How simple are the encoders and decoders? Beyond the code size benefits, simple encoders and decoders are easier to audit for correctness, resource consumption bounds, and security vulnerabilities.
- Decoder Speed How quickly can the entire file be scanned or processed? For comparison, JSON can be parsed at a rate of hundreds of MB/s.
- Queryability Often we only want a subset of the data given to us. Does the format allow
O(1)orO(lg N)path queries? Can we read the format without first parsing it into memory?
Size and parse-less queryability were my primary goals with JND. My hypothesis was that, since many JSON documents have repeating common structures (including string keys), storing strings and object shapes in a table would result in significant size wins.
Quickly glancing at the mainstream binary JSON encodings...
MsgPack
Each value starts with a tag byte followed by its payload. e.g. "0xdc indicates array, followed by a 16-bit length, followed by N values". Big-endian integers.
Must be parsed before querying.
BSON
Per spec, does not actually seem to be a superset of JSON? Disallows nuls in object keys, and does not support arrays as root elements, as far as I can tell.
Otherwise, similar encoding as MsgPack. Each value has a tag byte followed by a payload. At least it uses little-endian integers.
UBJSON
Same idea. One-byte tags for each value, followed by a payload. Notably, lists and objects have terminators, and may not have an explicit length. Kind of an odd decision IMO.
Big-endian again. Weird.
CBOR
IETF standard. Has a very intentional specification with documented rationales. Supports arrays of known sizes and arrays that terminate with a special "break" element. Smart 3-bit major tag followed by 5-bit length with special values for "length follows in next 4 bytes", etc.
Big-endian again... Endianness doesn't matter all that much, but it's kind of weird to see formats using the endianness that's less common these days.
CBOR does not support string or object shape tables, but at first glance it does not seem like CBOR sucks. I can imagine legitimate technical reasons to use it, though it is a quite complicated specification.
JND!
Okay! All of those formats have roughly the same shape. One byte prefixes on every value, value payloads in line (and thus values are variable-width).
Now it's time to look at the format I sketched up.
The file consists of a simple header marking the locations and sizes of three tables: values, strings, and object shapes.
The string table consists of raw UTF-8 string data.
In the value table, every value starts with a tag byte (sound familiar?). The high nibble encodes the type. The low nibble contains two 2-bit values, k and n.
Consider strings:
0011 kknn [1<<k bytes] [1<<n bytes] - string: offset, length into string table
0011 indicates this is a string value. k and n are "size tags" which indicate how many bytes encode the integers. The string offset is 1 << k bytes (little-endian) and the string length is 1 << n bytes. Once the size tags are decoded, the actual offset and length values are read following the tag byte, and the resulting indices are used to retrieve the UTF-8 text at the given offset and length from the string table.
Now let's look at objects:
1000 kknn [1<<k bytes] - object, object index, then <length> values of width n
The following 1 << k bytes encode the index into the object shape table, which holds the number and sorted list of object keys. Afterwards is a simple list of indices into the value table, each of size 1 << n bytes. The values are matched up with the keys in the object shape table.
Arrays are similar, except that instead of using an object index, they simply store their length.
This encoding has the property that lookups into an array are O(1) and lookups into an object are O(lg N), giving efficient support for path-based queries.
But there's a pretty big downside relative to MsgPack, CBOR, and the like. The cost of efficient random access is that the elements of arrays and objects must have a known size. Thus, the (variable-width) values themselves cannot be stored directly into the array's element list. Instead, arrays and objects have a list of fixed-width numeric offsets into the value table. This adds a level of indirection, and thus overhead, to JND. The payoff is that once a particular value is written (like a string or double-precision float), its index can be reused and referenced multiple times.
So how does this play out in practice? Net win or loss?
Size Benchmarks
I used sajson's standard corpus of test JSON documents.
- apache_builds Root object, largely consists of an array containing many three-element objects.
- github_events Mix of objects, arrays, and long URL strings.
- get_initial_state I can't share the contents of this document as it's from a project at work, but it's 1.7 MB of various entity definitions, where each entity type is an object with maybe a dozen or two fields.
- instruments A huge number of repeated structures and data -- very compressible.
- mesh 3D geometry. Basically a giant list of floating point and integer numbers.
- svg_menu Only 600 bytes - used to test startup and base overhead costs.
- twitter List of fairly large objects, many long strings.
- update-center From Jenkins. Mostly consists of an object representing a mapping from plugin name to plugin description.

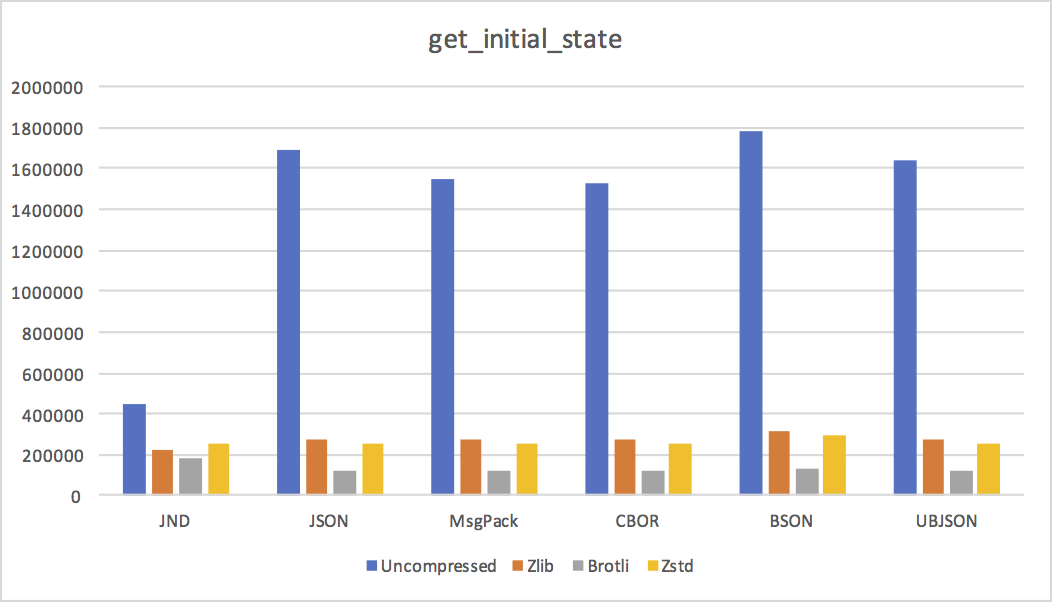
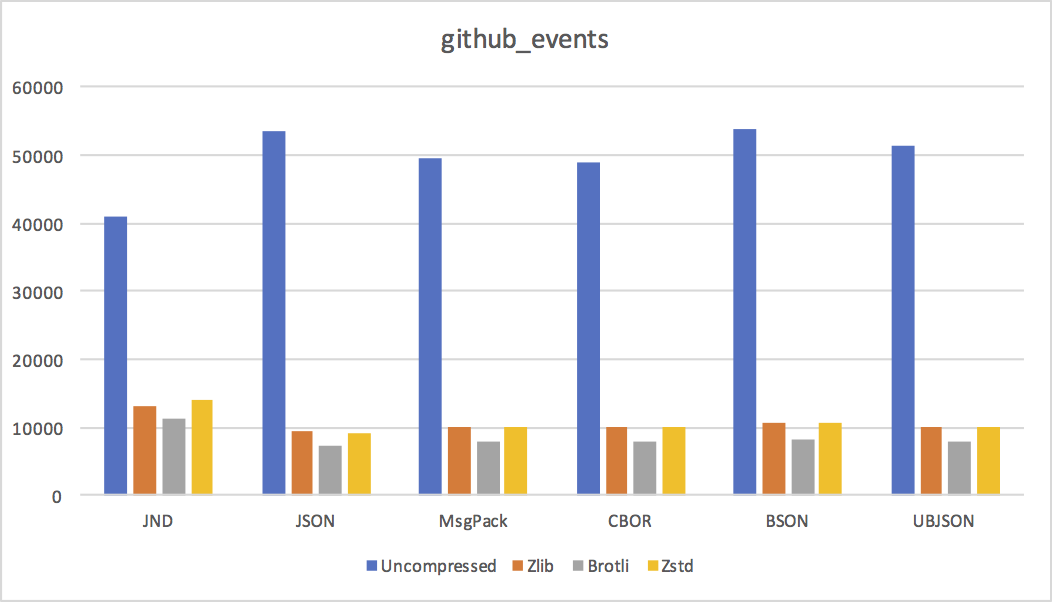
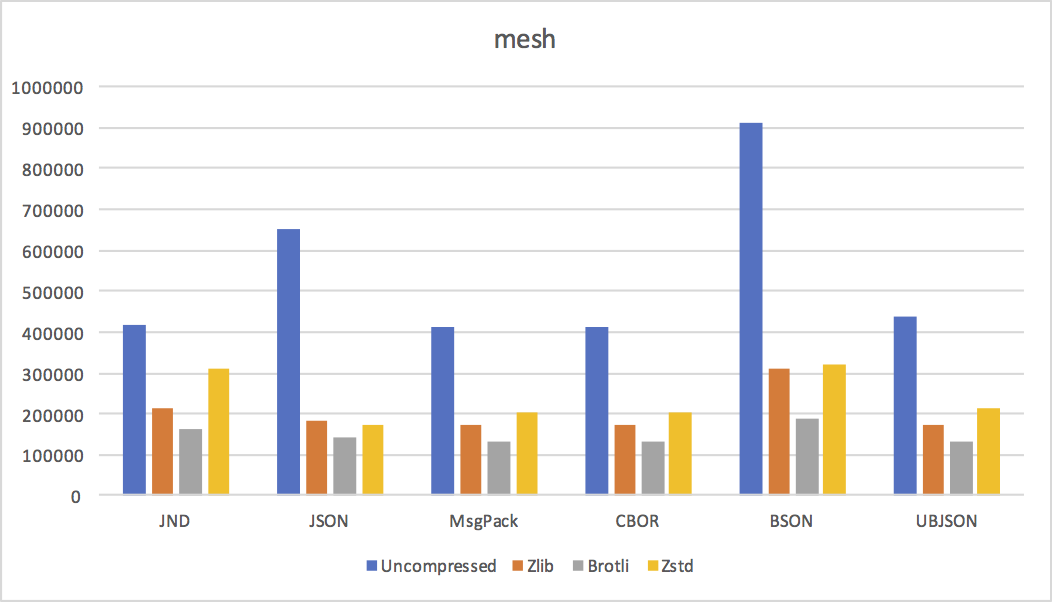

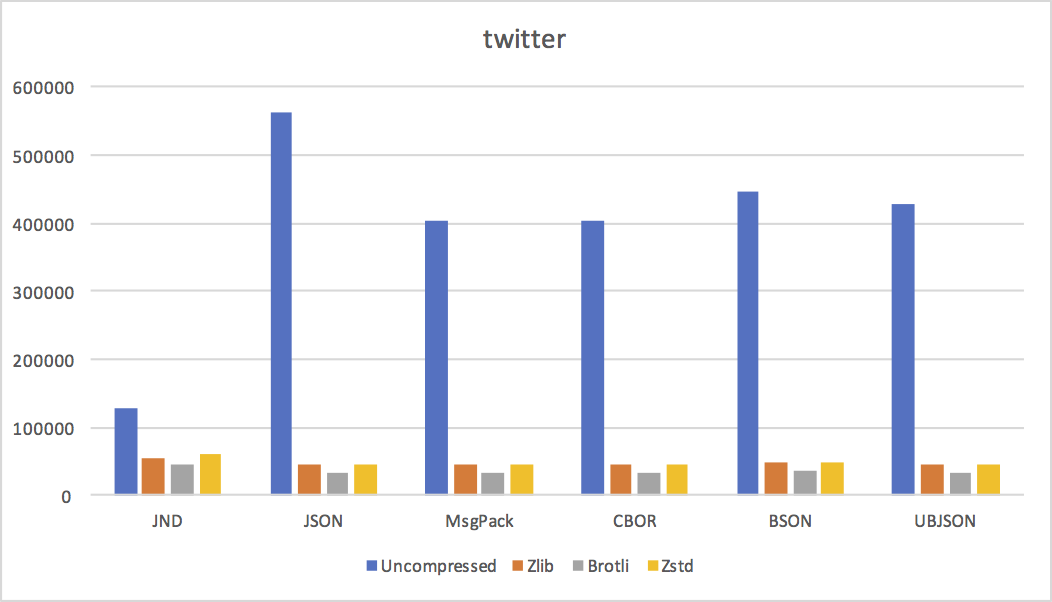
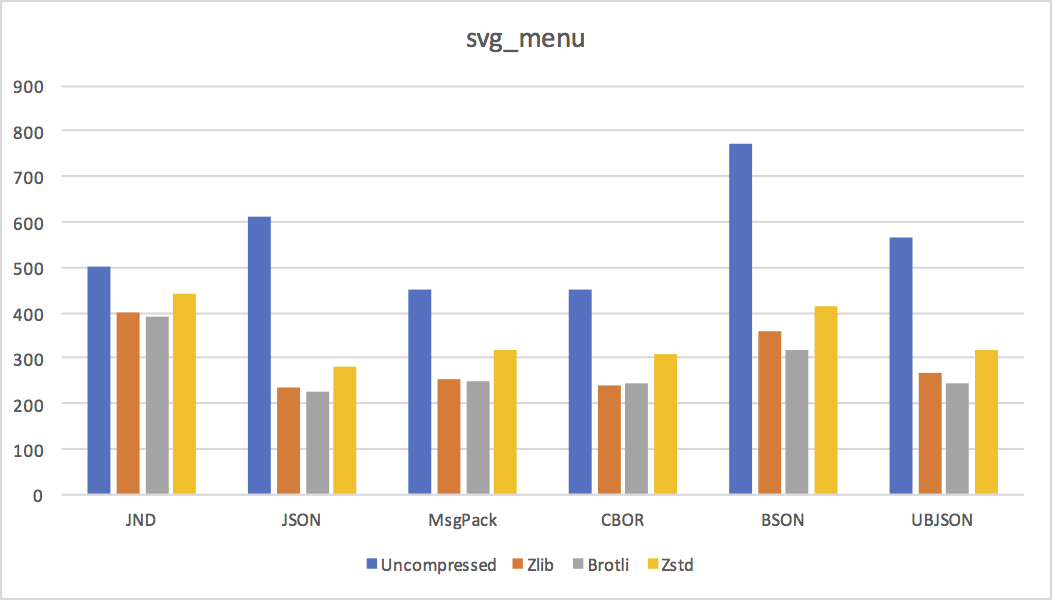
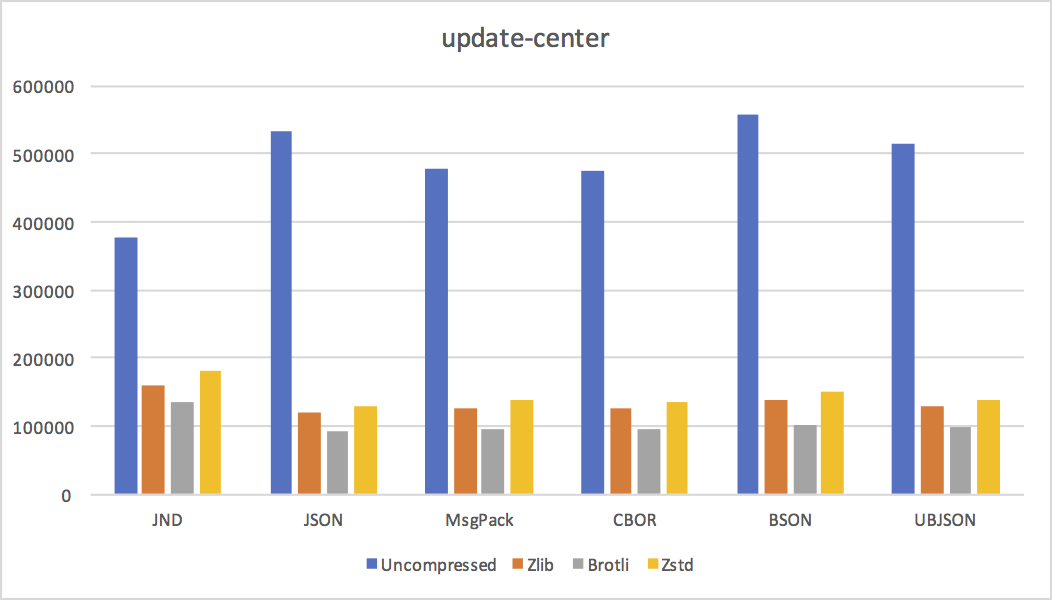
Conclusions
We can draw a few conclusions from these results.
- As a wire replacement for the JSON data model, there's no apparent reason to use BSON or UBSON. I'd probably default to MsgPack because it's simple, but CBOR might be okay too.
- The current crop of binary formats don't compress any better than JSON itself, so if size over the wire is your primary concern, you might as well stick with JSON.
- Except for small documents, where JND's increased representation overhead dominates, JND is pretty much always smaller uncompressed. As predicted, reusing strings and object shapes is a big win in practice.
- LZ-style compression algorithms don't like JND much. Not a big surprise, since they don't do a good job with sequences of numeric values. I expect delta coding value offsets in arrays and objects would help a lot, at the cost of needing to do a linear pass from delta to absolute at encode and decode time.
JND's disadvantage is clear in the above graphs: while it's smaller uncompressed, it does not compress as well as JSON or MsgPack. (Except in cases where its uncompressed size is dramatically smaller because of huge amounts of string or object shape reuse.)
Where would something like JND be useful? JND's big advantage is that it can be read directly without allocating or parsing into another data structure. In addition, the uncompressed data is relatively compact. So I could imagine it being used if IO is relatively cheap but tight memory bounds are required.
Another advantage of JND is a bit less obvious. In my experience using sajson from other languages, the parse itself is cheaper than converting the parsed AST into values in the host language. For example, constructing Swift String objects from binary UTF-8 data was an order of magnitude slower than the parse itself. In JND, every unique string would naturally be translated into host language String objects once.
If you'd like to play with my experiments, they're on GitHub at https://github.com/chadaustin/jnd.
Future Work?
It was more work than I could justify for this experiment, but I'd love to see how Thrift or Protocol Buffers compare to JND. JND is a self-describing format, so it's going to lose on small messages, but when data sizes get big I wouldn't be surprised if it at least ties protobufs.
Update: Forgot to mention decode times. I didn't have time to set up a proper benchmark with high-performance implementations of each of these formats (rather than whatever pip gave me), but I think we can safely assume CBOR, MsgPack, BSON, and UBSON all have similar parse times, since the main structure of the decoder loop would be the same. The biggest question would be: how does that compare to JSON? And how does JND compare to both?
This is some Rockstar stuff, Chad!
I've written a CBOR implementation and it's not as complicated as you make it out to be. It does offer an "escape" mechanism in encoding in the form of semantic tagging of data, and because of that, it does (or rather, there's a registered extension [1]) to handle string references (a string appears once, then afterwards, you can reference it via a small integer value [2]). I don't quite understand what you mean by "CBOR does not support string or object shape tables" as I've been able to encode some pretty wild things.
[1] https://www.iana.org/assignments/cbor-tags/cbor-tags.xhtml
[2] There's another tag extension that allows references to arrays and maps.
Ah, thanks for the heads up. I should have said baseline CBOR. I wonder if everyone implements the relevant tags?
Look into flexbuffers it is almost a 1 to 1 mapping of json data (except booleans however there is a pull request for that)
https://google.github.io/flatbuffers/flexbuffers.html
ArangoDB VelocyPack has similar goals. In particular access to subdocuments (queryability), other goals are common to most of the formats. (I'm not advocating using VelocyPack, I'm currently a fan of CBOR)
They are big endian because that is network endian, BSON is the weird one:
https://en.wikipedia.org/wiki/Endianness#Networking
Otherwise interesting article, thanks.